
Researched the challenges Infineon developers face when seeking technical support the answers and solutions were scattered across documentation pages, community forum threads, and GitHub repositories with no unified way to query them.
Conducted analysis of common query types to understand that users needed different kinds of help: some needed product hardware guidance, others needed software/tool support, and many needed working code examples.
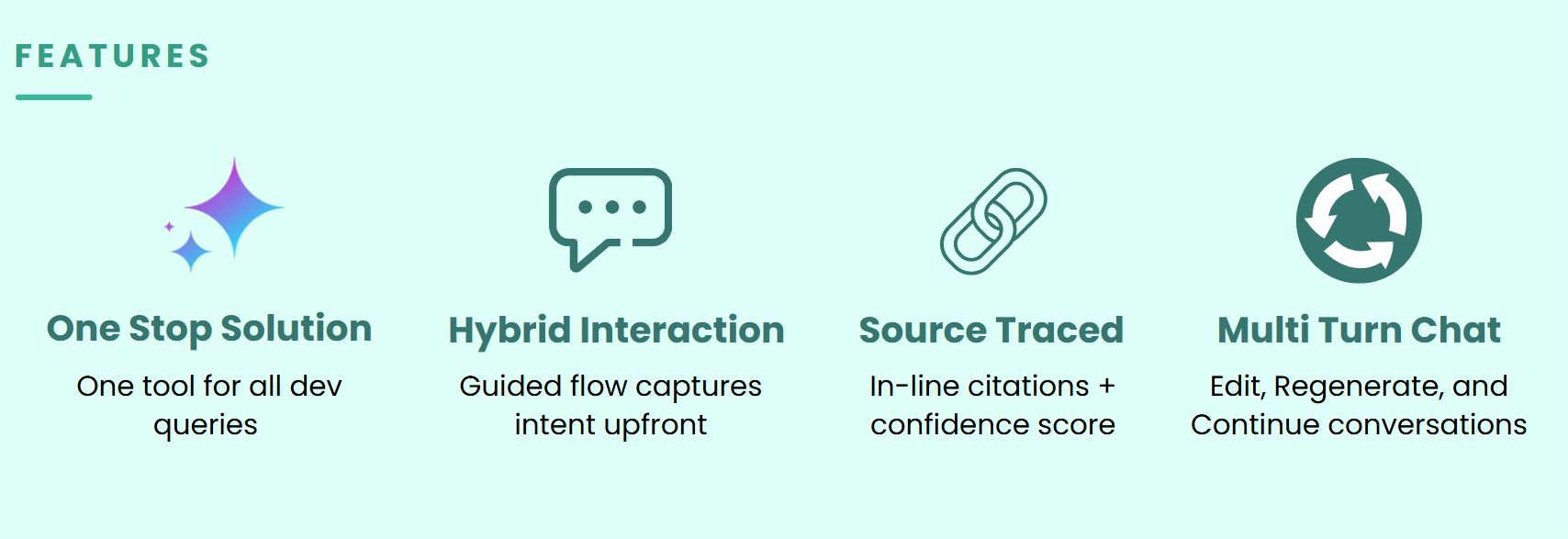
Defined the scope of the chatbot by establishing three intent categories; product, software, and both. This help to structure how queries are handled and what sources are searched.
We also identified key success criteria: responses must be grounded in retrieved sources (no hallucination), confidence must be measurable, generated code must be syntactically valid, and out-of-domain queries must be rejected cleanly.
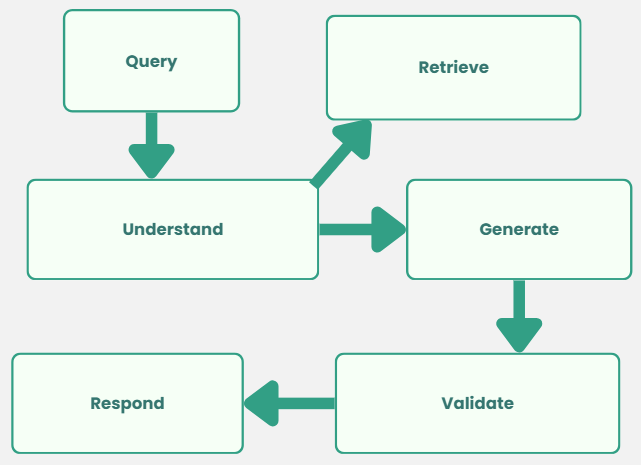
Built a RAG (Retrieval-Augmented Generation) pipeline that converts user queries into vector embeddings, compares them against a database of pre-indexed documents, forum posts, and GitHub code, and blends semantic and keyword search results to surface the most relevant content.
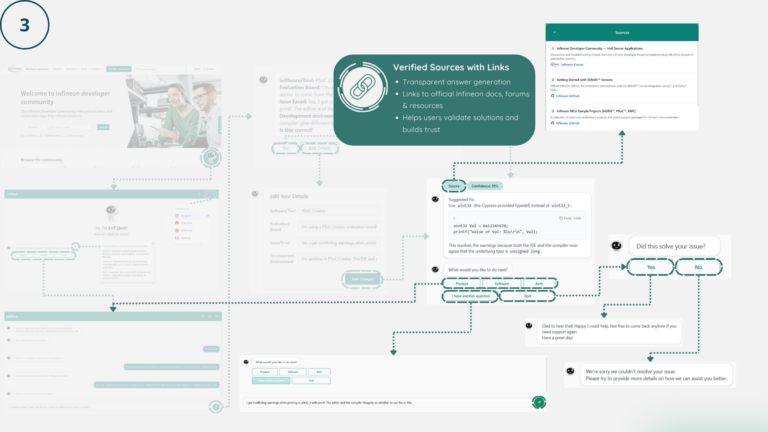
Layered on top of retrieval are NER-based query enrichment, code intent detection, confidence scoring, syntax validation with self-healing retries, and a streaming response interface with clickable source citations, delivering accurate, traceable, and real-time answers to technical queries.
This project is built on a modern full-stack architecture designed to deliver accurate, grounded, and real-time responses to technical queries.

At the core of the system is a two-stage fusion retrieval pipeline that converts user queries into vector embeddings using OpenAI’s embedding model, then compares them against thousands of pre-indexed documents, forum posts, and GitHub code snippets stored in a PostgreSQL vector database (pgvector).
A parallel keyword search runs simultaneously, targeting exact technical terms extracted via Named Entity Recognition (NER), and both result sets are blended using Reciprocal Rank Fusion (RRF) to surface the most relevant content. This approach ensures results are found by meaning, not just by exact word match.
Retrieved content is passed to a large language model either Claude 3.5 Sonnet via AWS Bedrock or GPT-4 which generates a grounded response using only what was retrieved, preventing hallucination.
For code-related queries, a specialised BGE code embedding model handles retrieval, and responses go through automatic syntax validation with a self-healing retry mechanism that silently corrects errors before the answer reaches the user.
Confidence scoring is applied throughout, triggering live GitHub fallback fetches and warning injections when retrieval quality is low.
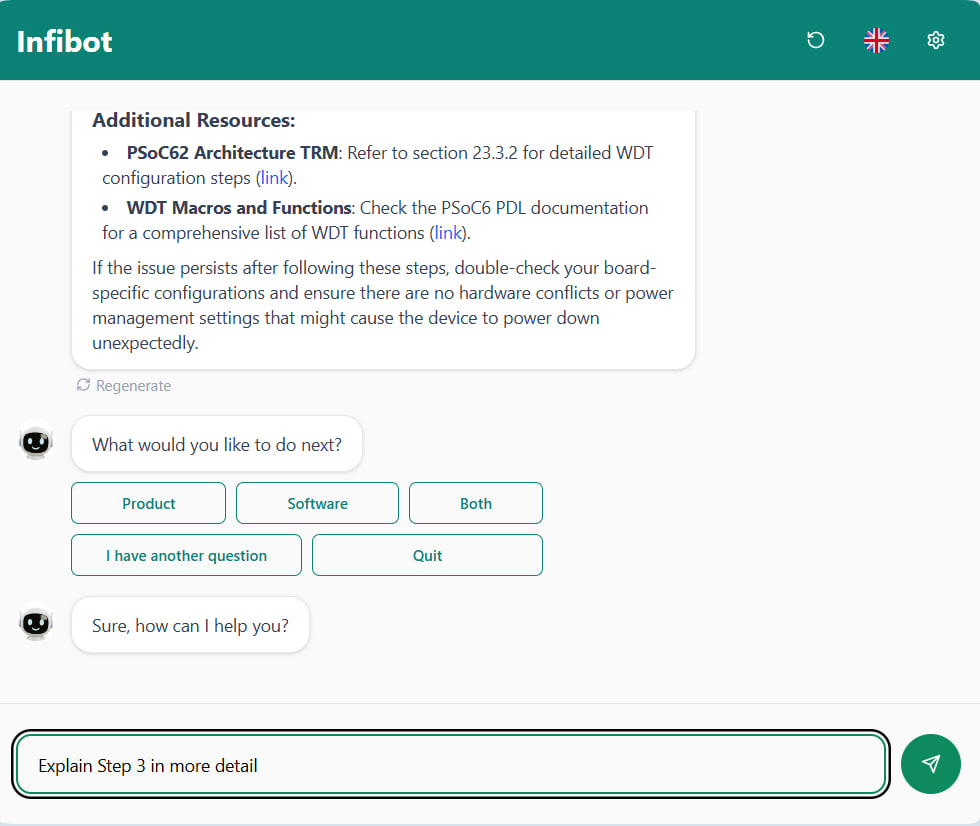
The frontend is built with React and TypeScript, featuring a structured multi-phase conversation flow where users select their intent (product, software, or both) before querying.
Responses are delivered via Server-Sent Events (SSE) for real-time token streaming, rendered with GitHub-flavoured Markdown, syntax-highlighted code blocks via Prism.js, and numbered source citations that link directly to the original forum post or GitHub file.
End-to-end tests are handled with Playwright, and unit tests with Vitest, ensuring reliability across the full user journey.