Problem
SMEs in Singapore face increasing pressure to comply with the PDPA. However, many SMEs struggle to. According to the Personal Data Protection Commission (PDPC):
- 68% of data breaches involve people.
- 83% of firms found PDPA beneficial.
- 55% of firms said they need PDPA help.
Features
AI4PDPA provides a conversational assistant for grounded answers to questions on PDPA, a learning platform for fuss-free staff training and testing, and an analytics dashboard for efficient system monitoring.
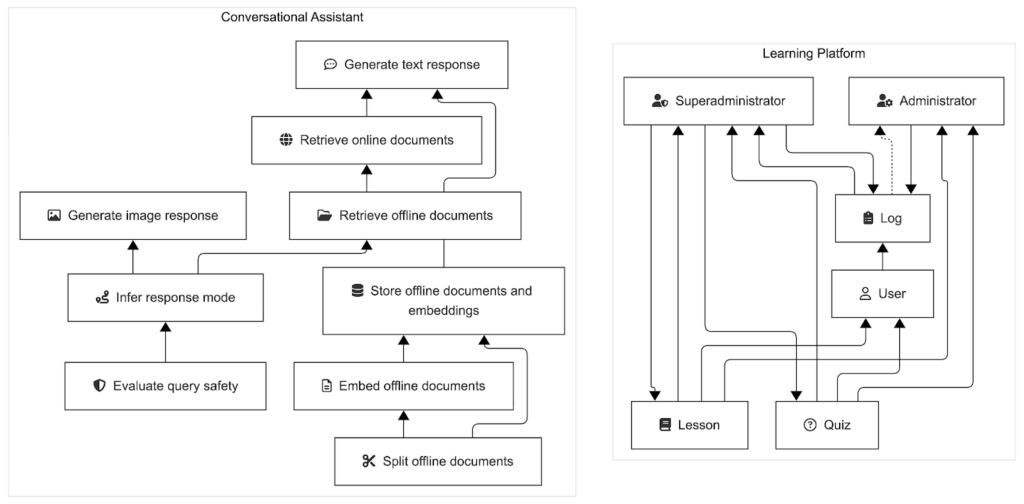
Our conversational assistant composes multiple functions seamlessly. Image and language models use retrieval-augmented generation and web search to infer query safety and response modality before generating compressed, citation-backed text or image responses to queries.
Offline, the system starts with a curated corpus of 6 documents about the PDPA from official sources including the PDPC. These documents were recommended by our partners, and remain public information. First, we split each document into chunks using page-level chunking, as we concluded from early experiments that many documents (especially legal ones) already respect page boundaries. Then, we embedded each chunk into a vector capturing chunk semantics using an embedding model. Finally, we stored each document with its embedding in a vector store.
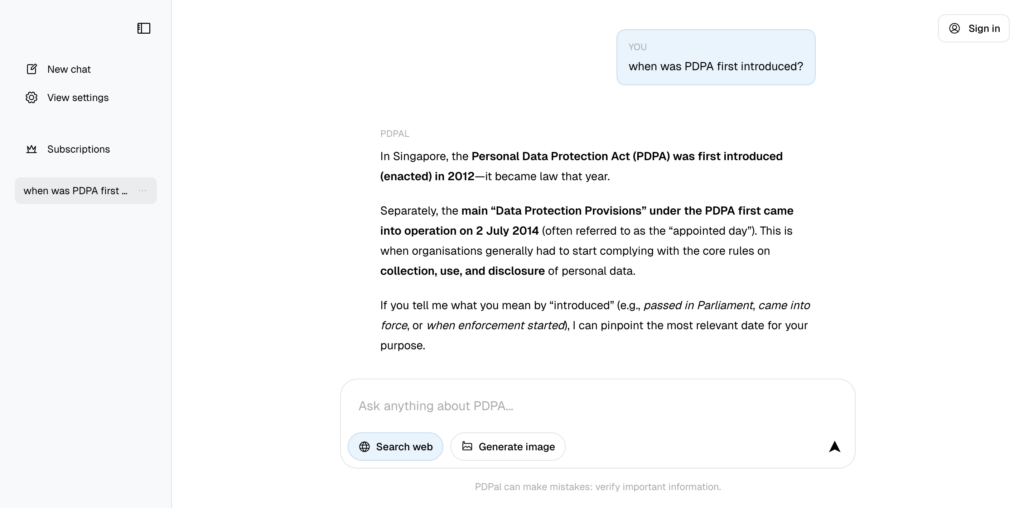
Online, the system opens its doors to receiving queries through a graphical user interface. The user interface was designed to be simple and intuitive, following the design language of popular predecessors such as OpenAI’s ChatGPT and Google’s Gemini. First, the system calls a text model with structured outputs to evaluate the safety of a query by checking it for harmful (or off-topic) content (e.g. profane language, strange characters, etc.). If the query is flagged, then the system returns a default response (e.g. “Sorry! I cannot help with that.”). Second, the system calls a text model with structured outputs to infer the intended response mode by inferring a response modality (i.e. whether the response should be image or text) and web search requirement (i.e. whether to search the web). If the inferred response modality is image, then the system calls an image model to generate an image response; the image is compressed by downsampling and iterative quality reduction until the image size falls within the size limits of our conversation database. Otherwise, if the inferred response modality is text, then the system retrieves web results if the web search requirement is truthy, and the top 3 chunks stored in the vector store by nearest-neighbour search under embedding cosine similarity; the retrieved information is used to prompt a text model to generate a citation-backed text response. Responses have progress indicators (e.g. “Pondering…”) to maintain user engagement.
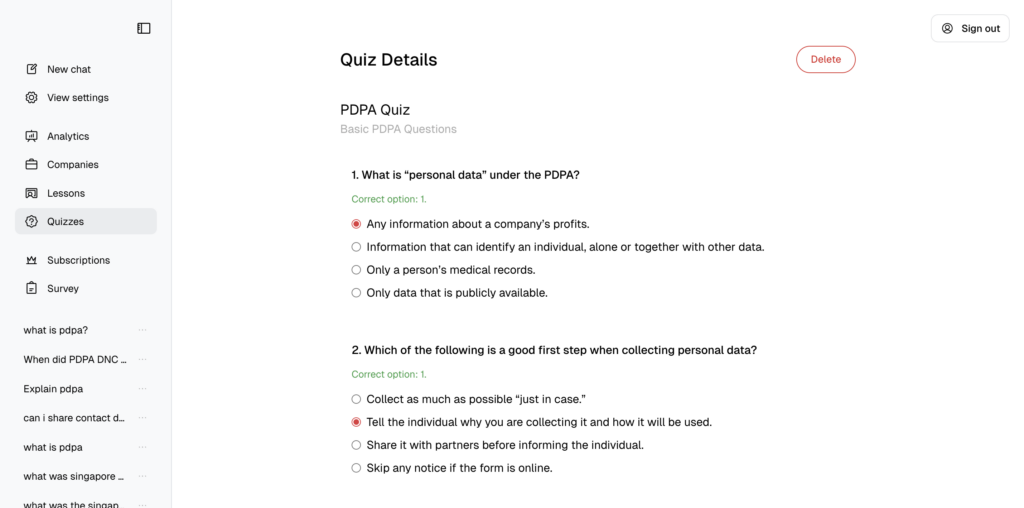
Our learning platform bears a simply crafted interface that allows for the access and creation of lessons and quizzes, and tracking of quiz progress, depending on user role. Users can access lessons and quizzes, administrators can track quiz progress, and superadministrators can write lessons and quizzes.
Superadministrators can upload lessons as files for users to download and view. Superadministrators can upload or write quizzes in the Aiken format for users to attempt. Administrators can see quiz results on the level of question correctness.
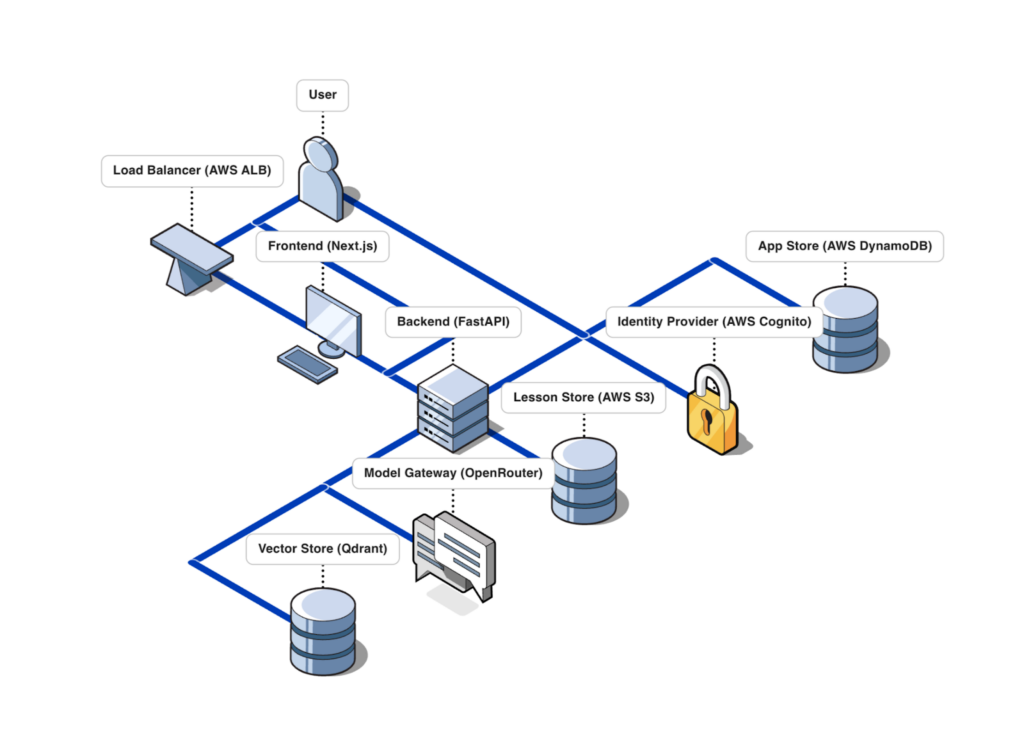
The app is served using NextJS and FastAPI due to their community support, popularity, and speed. The vector store uses Qdrant locally, as we concluded that this would be a fast and maintainable way to store and retrieve the number of embeddings we would eventually have. The model calls use the OpenRouter API, as we concluded that this would be a cheap way to serve users at scale and low latency.
The code was written in a modular way that allows models to be easily changed at any time for testing and deployment: when a new model is released on OpenRouter, it can be swapped in by updating a single line of code.
Acknowledgements
We would like to thank everyone who has contributed to the success of this project.

