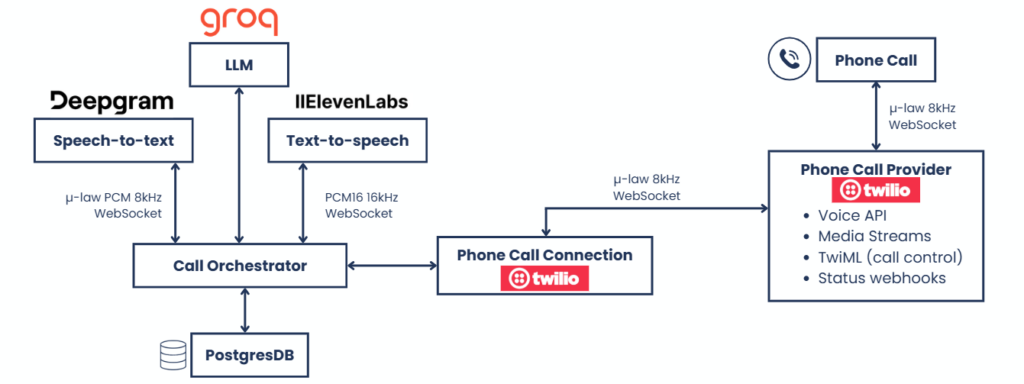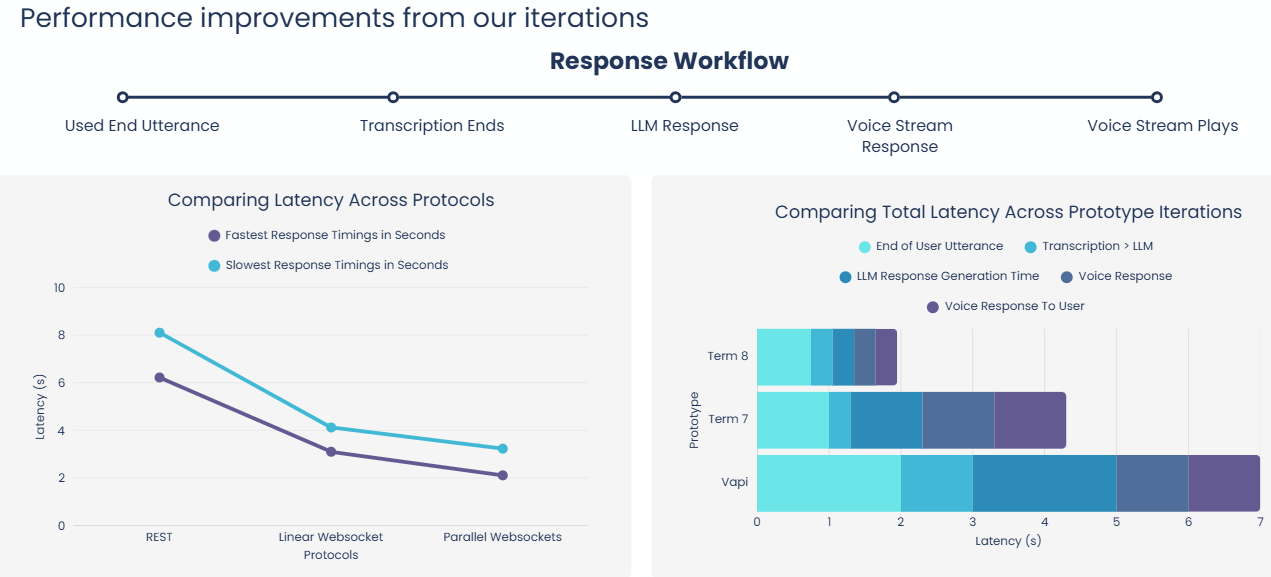
Low Latency
Doby responds to customers in under a second, powered by a parallel WebSocket pipeline combining Deepgram for speech-to-text, Groq for language model inference, and ElevenLabs for voice synthesis. Through three iterations of optimisation — including Enthusiastic End Utterance prediction and Overlap Stream Piping — we reduced end-to-end response time from a 6–8 second baseline to approximately 0.8 seconds, an 88% improvement. Conversations feel natural, not like waiting on hold.
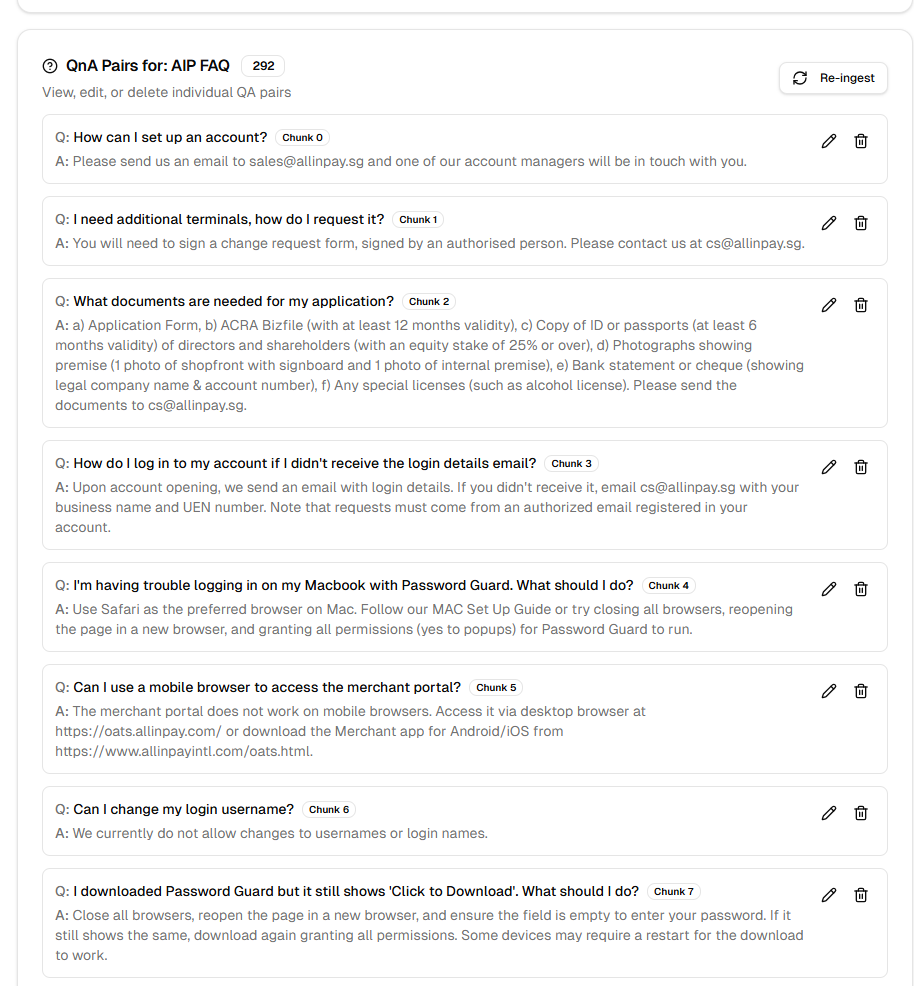
Context Aware
Upload your company documents — text, PDFs, or images — and Doby builds a knowledge base specific to your business. Our multimodal RAG system converts all ingested content into structured question-and-answer pairs, then embeds them for precise cosine-similarity retrieval grounded in the last 20 conversational turns. This achieves 90% retrieval accuracy during live calls, so Doby always knows what to say and never makes things up.
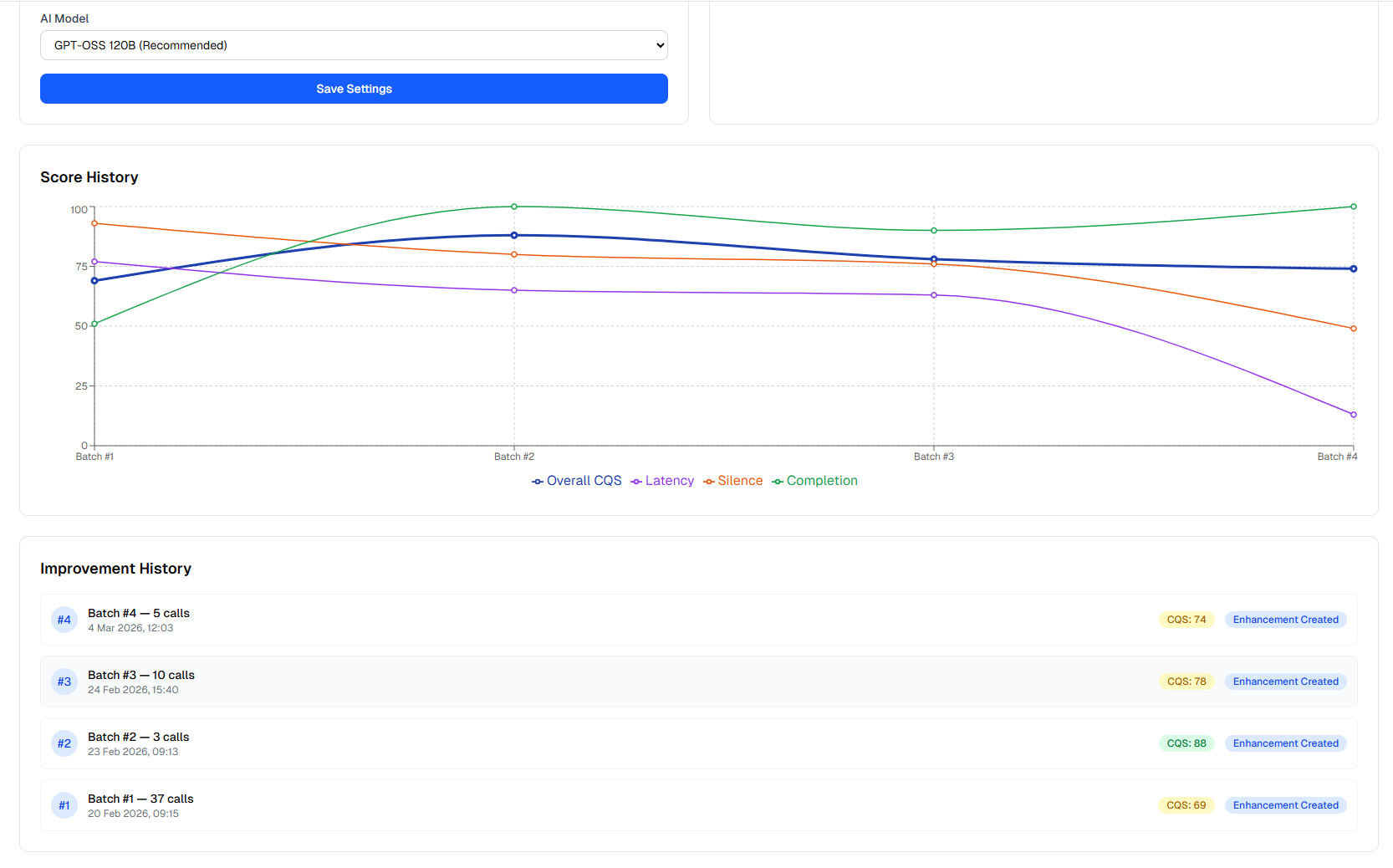
Self Improving
Every call is scored by our proprietary Call Quality Score (CQS), a hybrid reward function measuring response latency, user interruptions, and silence patterns. An LLM-driven pipeline then analyses weak spots and generates improved call scripts automatically. In testing, this raised CQS from 69 to 90 — a 30% improvement — while compressing script iteration cycles from 20 minutes to under 5. Doby gets measurably better with every conversation.
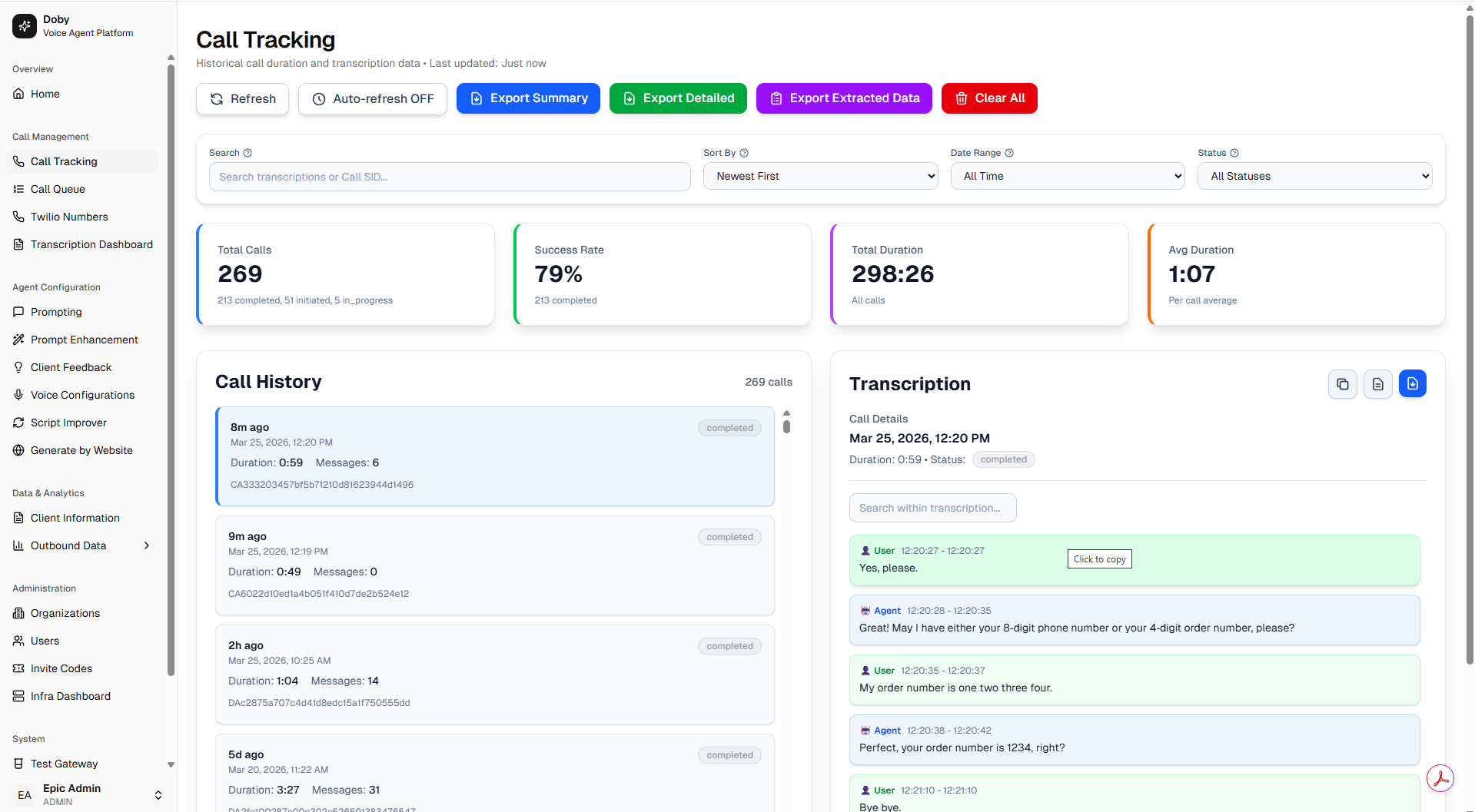
Business Dashboard
Track call volume, response times, resolution rates, and full call transcripts from a single clean dashboard. You always know how Doby is performing and what your customers are asking about.
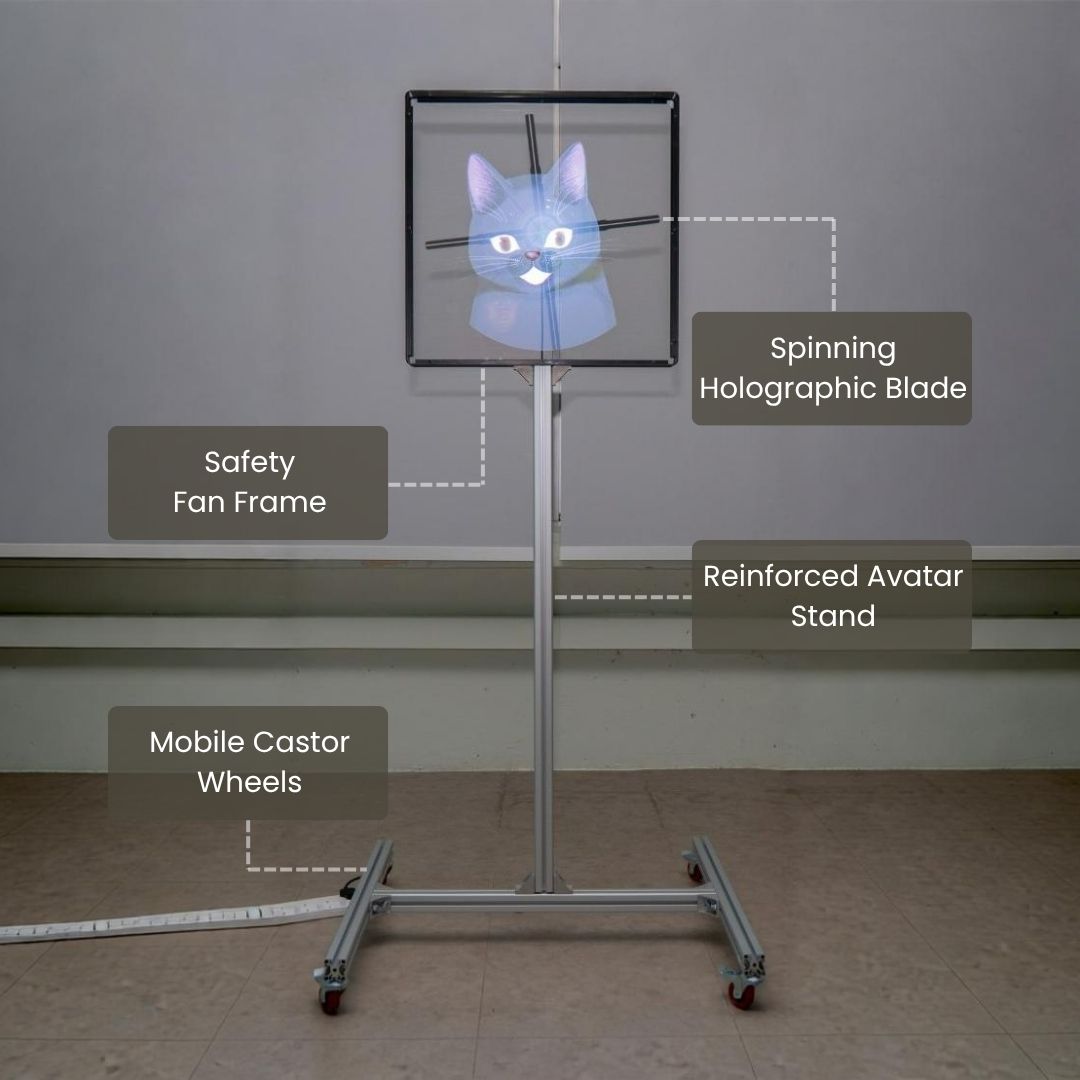
Holographic Avatar
Customers do not just hear Doby. They can see a live holographic avatar on screen, a human-like face that builds trust and makes every interaction feel personal. It brings AI efficiency together with the warmth of face-to-face service.
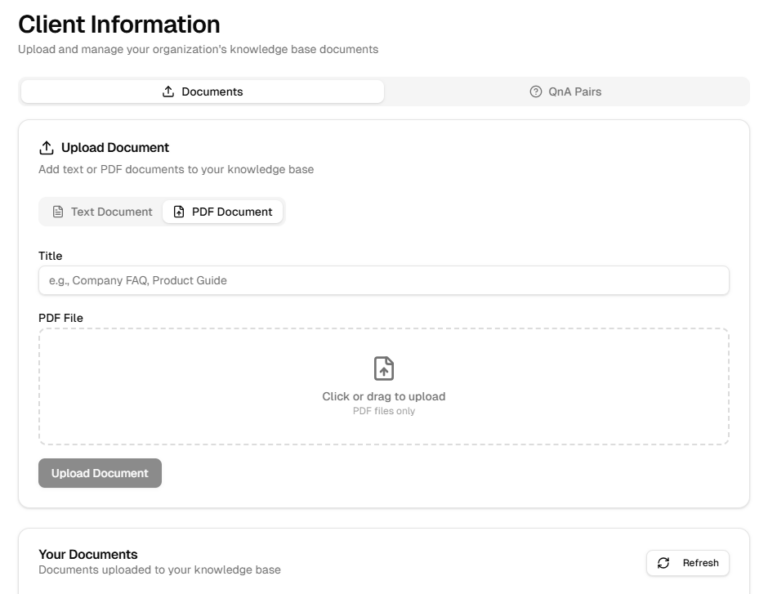
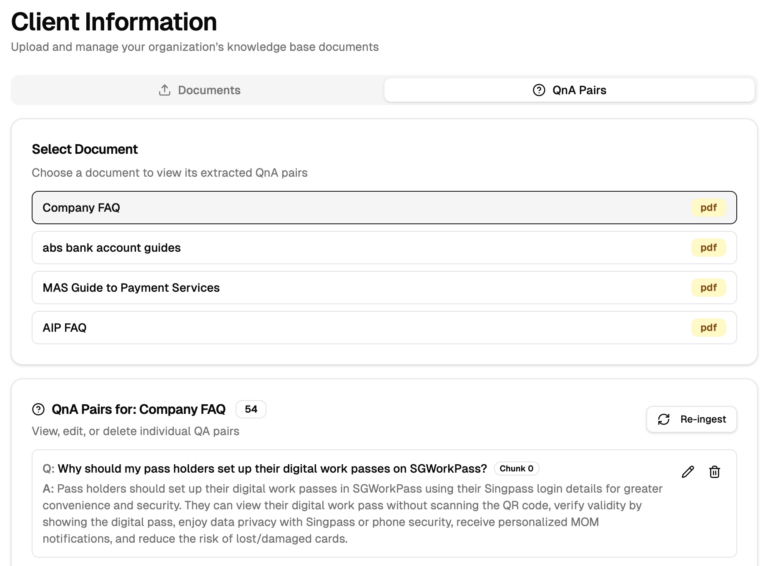
Add your business FAQs, product guides, existing customer service scripts, pricing sheets or even your Website that you want Doby to know as context when answering your customers.
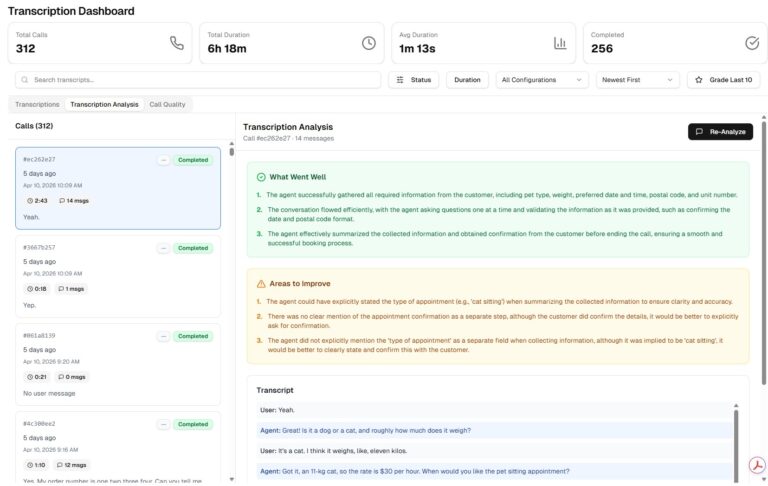
Doby automatically processes your business context to prepare call scripts for your customers that are detailed and compelling.
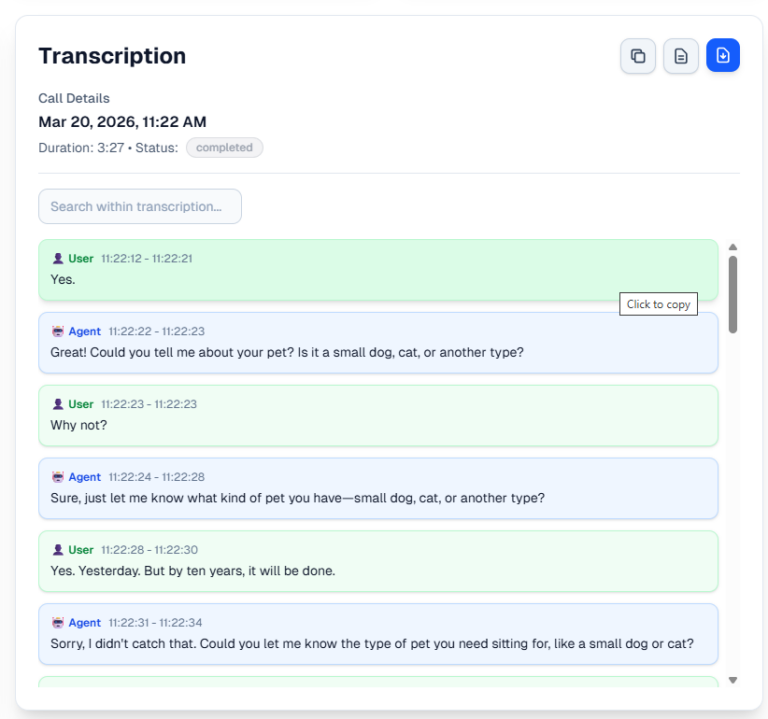
Doby picks up your customer calls 24/7. Speech is transcribed in real time, matched against your knowledge base, and answered in a natural voice, all 0.8s. If the caller interrupts mid-response, Doby stops and listens and updates accordingly.
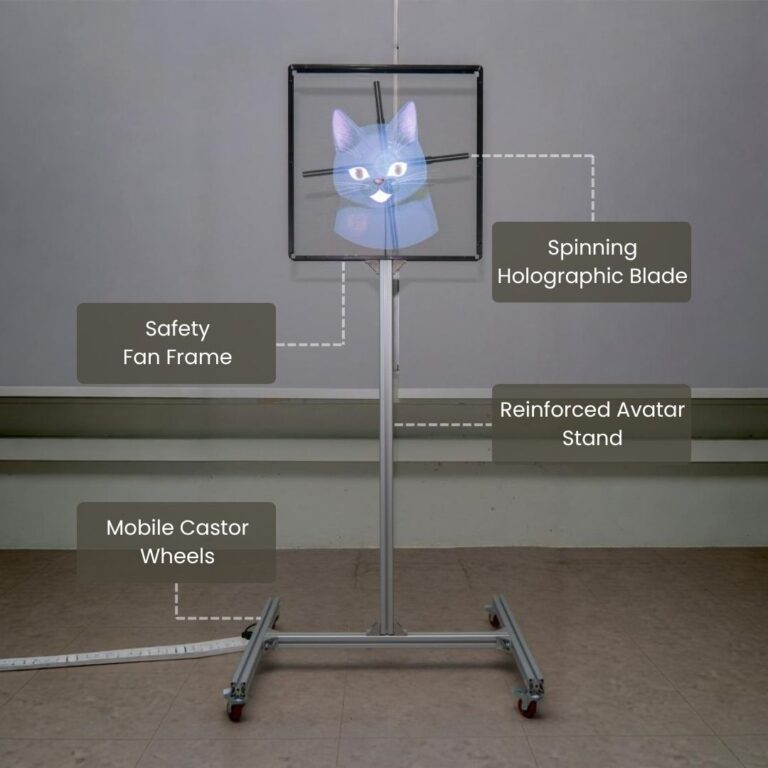
Doby comes with a first-in-market holographic avatar for physical locations. It displays our call agent with live lifelike lip-sync, body sway, and 3D depth, increasing your customer trust and engagement by ~30% according to research, potentially increasing customer retention and lifetime value. The avatar character design can even be customised to your Company's branding or mascot.
Doby reviews each call, evaluates performance, identifies gaps, and improves its responses over time, all automatically. This lets you operate with peace of mind that Doby is always optimising for your customer satisfaction.
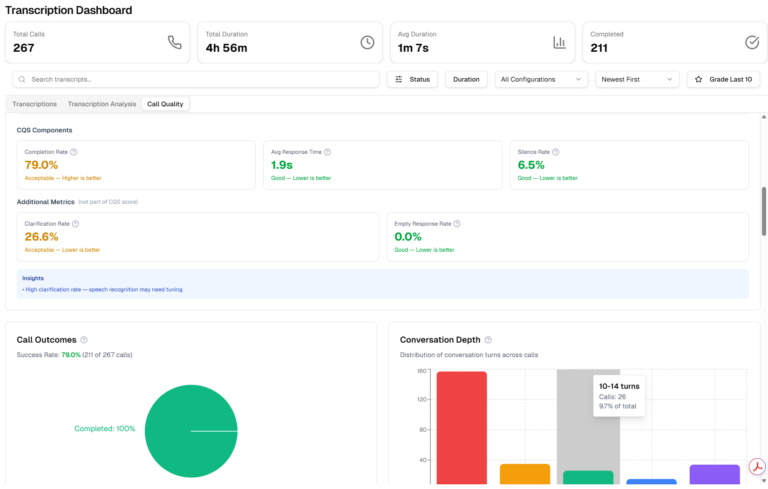
Check call logs, monitor performance, and summarise what your customers are asking, change settings, whenever you want. Doby displays all data and updates in an intuitive dashboard. So you can focus on growing the business instead of worrying about customer service.