
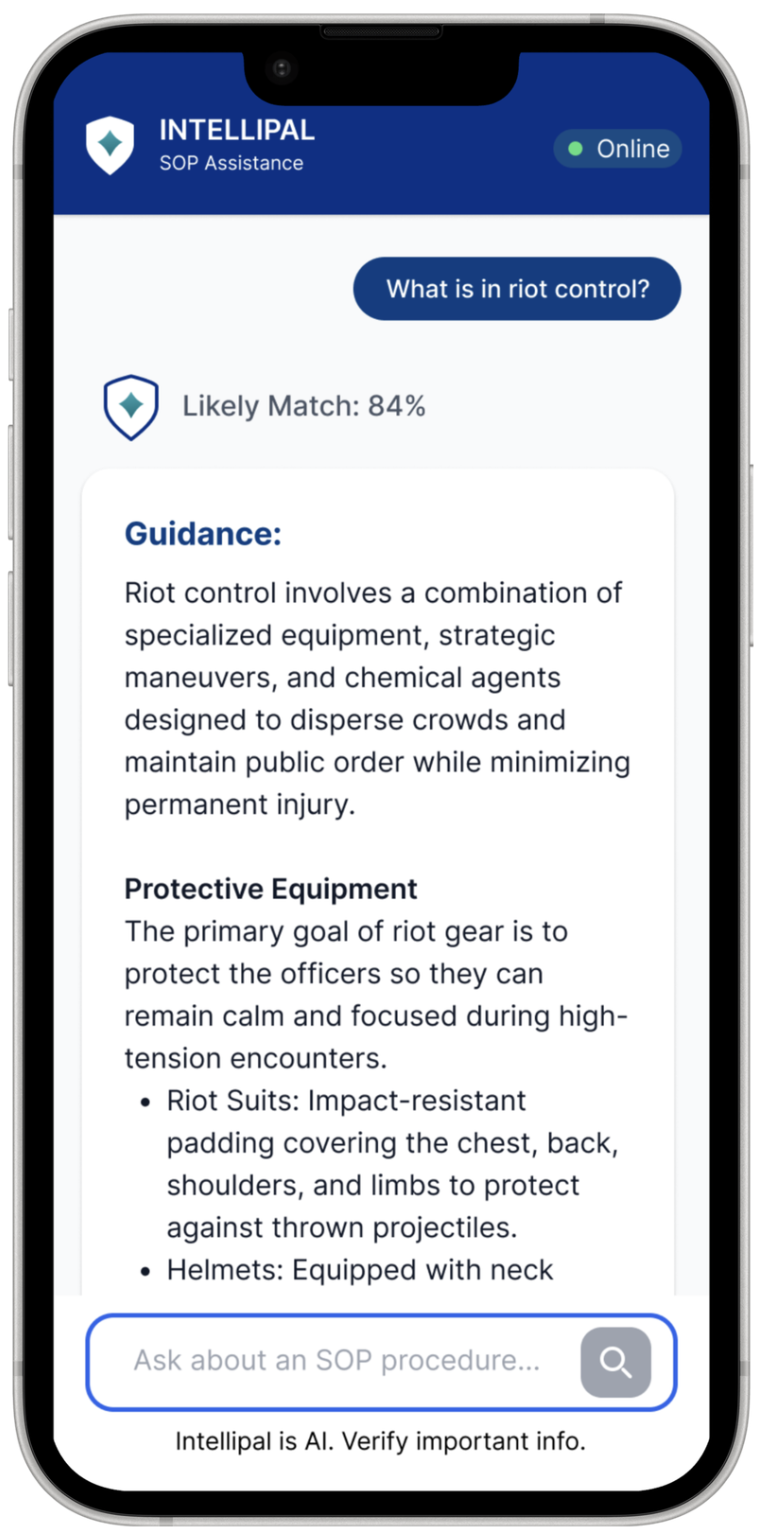



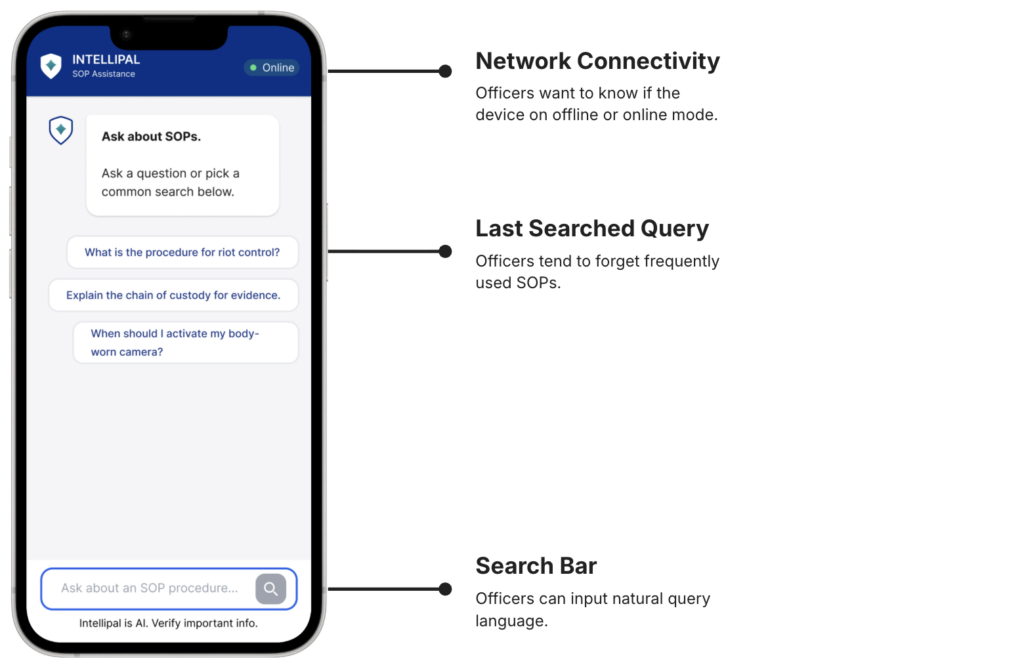
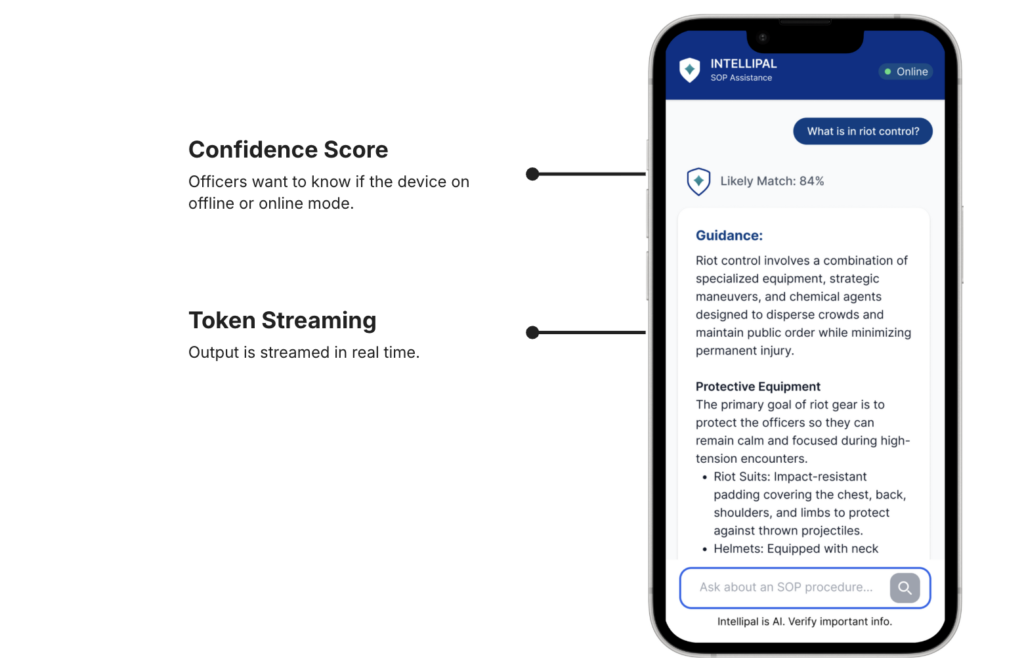
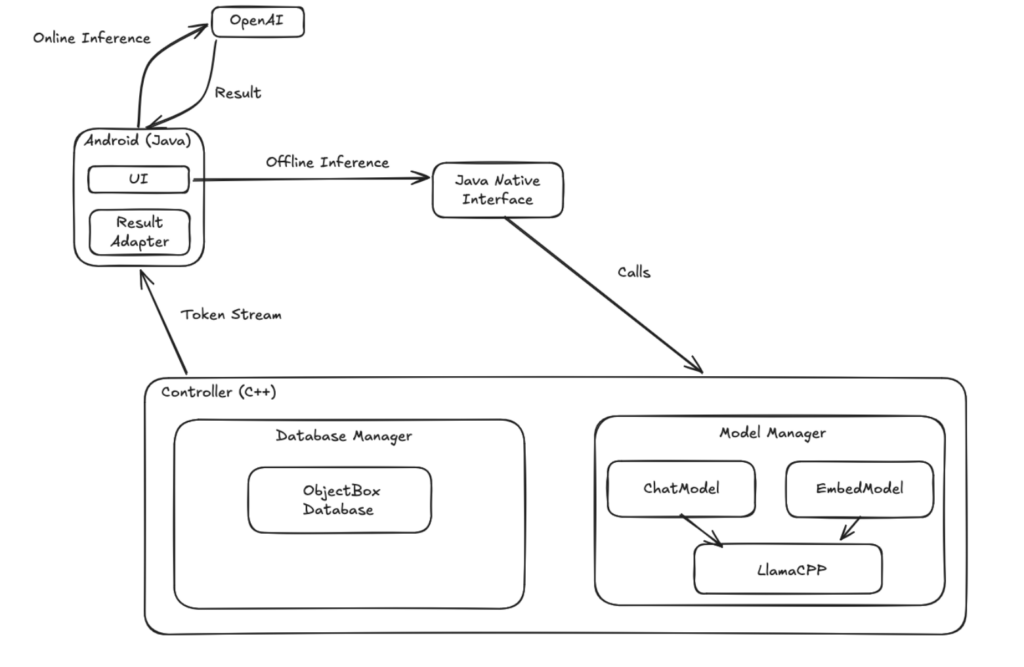
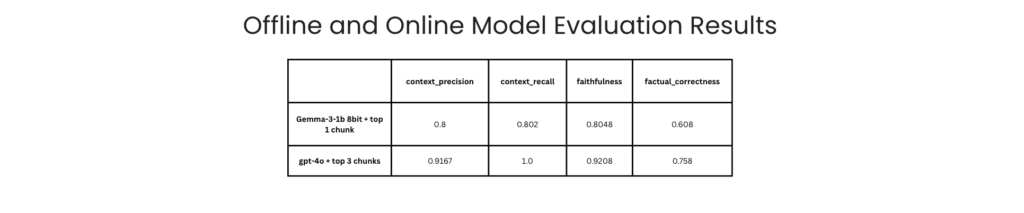
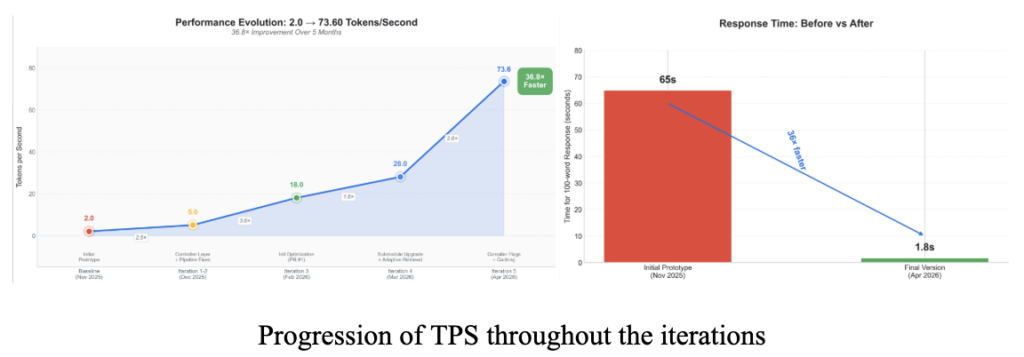
The app is quite easy to use and intuitive. Would have loved to have something like this in my starting days, so don't need bother supervisor as much
This app can be quite helpful to new joinees while on the way to the site.
This can be resourceful for times we face connectivity blackspots like in mall basements or carparks.

