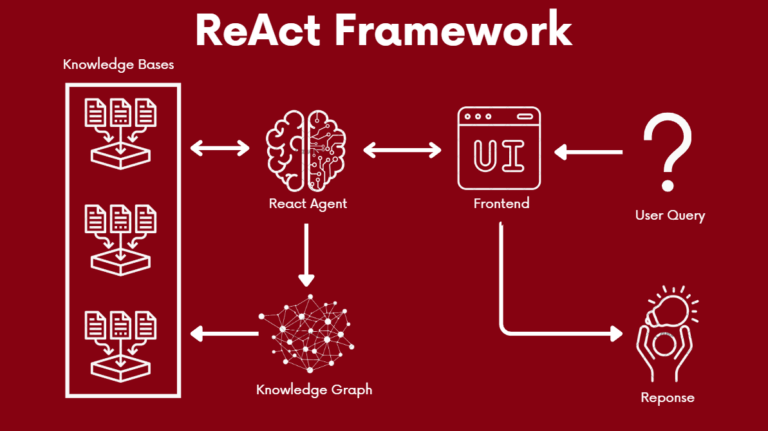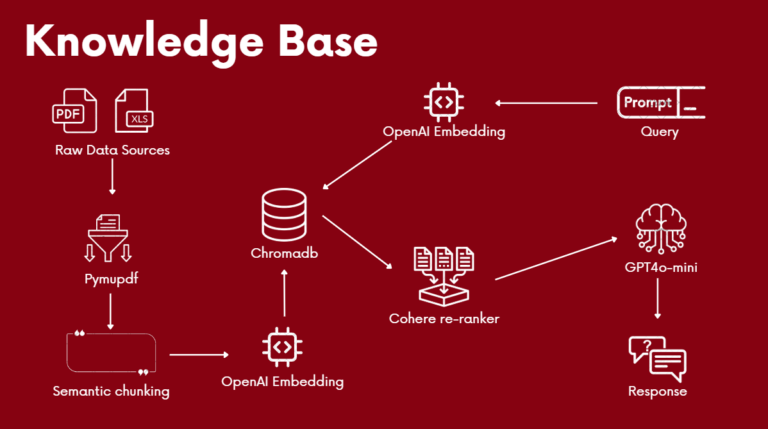

A single Knowledge Base in our project is akin to having a generic single retrieval augmented generation (RAG) system. We decided to modularize the RAG system to allow for the creation of multiple Knowledge Bases as we wanted a Knowledge Base to be considered a domain expert that can answer queries in their relevant fields.
The reason we decided to split the information into specific sectors with different knowledge bases instead of storing all the information into a single knowledge base was to reduce the time needed to search through the vector database. Smaller vector databases would be more efficient and accurate in retrieving the information required by the agent, compared to having one large vector database which could have lower accuracy and take longer to retrieve the information.
Given the wide array of powerful tools available, the following are some of the makeup solutions we have employed in developing the Knowledge Base:
The Knowledge Graph is a complementary system to the Knowledge Base. It serves as a modifier for the original query using relational properties provided by graph structures to search for related sections, acting as background knowledge for the subsequent querying of the Knowledge Base. This Knowledge Graph is a relational database built using Neo4j’s graph database system, which has good query performance even when the database gets larger.
Neo4j uses Structured Query Language (SQL), more specifically known as Cypher Query Language (CQL), which requires structured procedures for querying and manipulating data, as opposed to a vectored database.
The Knowledge Graph provides useful features such as:
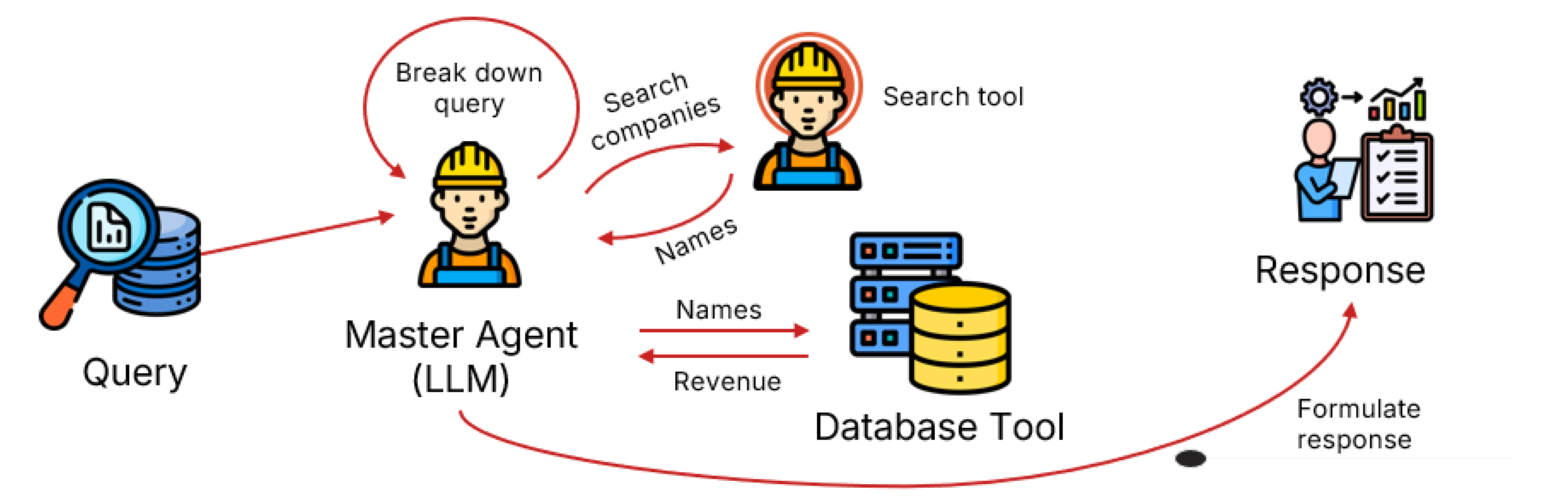
Agentic refers to the capacity to act independently and achieve outcomes through self-directed actions and informed decision-making and our GAR is all that.
GAR employs a variety of methods to dynamically create different tools to determine the next best action. Leveraging Langchain library in combination with OpenAI LLM, GAR is able to autonomously set up the tool creation process, allowing it to adapt to diverse scenarios. GAR intelligently evaluates a task, utilizes the different tools, and creates new ones to enhance its decision-making capabilities if deemed necessary. This system ensures efficiency by optimizing tool selection and integrating reasoning frameworks called ReAct to generate the next best action.



Our team would like to thank our Capstone instructors: Dr Cyrille Jegourel & Dr Susan Wong for their valuable advice which were pivotal to GAR’s success.
The team would like to thank our ST Engineering mentors, Mr Ween Jiann Lee and Chew Kay Thiam Dennis, for their guidance and help in providing the support we needed.