










Security personnel in high-noise environments—such as airports and shopping malls—often struggle to capture speech from civilians or suspects during critical encounters. The combination of overlapping conversations, environmental noise, public announcements, and unpredictable acoustic conditions severely impacts the intelligibility of spoken instructions and alerts. These conditions can lead to misunderstandings, delayed responses, and potentially missed threats.
Traditional microphone systems and standard communication tools often fall short in such dynamic settings, struggling to isolate speech from ambient noise. As a result, frontline personnel are left without the clarity they need to act swiftly and accurately in high-stakes situations. A new approach is essential—one that ensures every word is heard, captured, and understood in real time.

After identifying a broad communication issue in the field, the team conducted a series of controlled experiments to convert this vague challenge into measurable, actionable insights. Through on-site testing and user observation, we pinpointed three core obstacles: the prevalence of high-noise environments (averaging above 70dB), the dependency of existing products on internet access, and the lack of clarity in captured speech.
These findings allowed us to sharpen our focus and define the exact needs of security personnel operating in chaotic spaces. We refined our problem statement to the following:
How might we create a speech capturing device that enhances, playback, and transcribes audio in noisy or crowded environments?

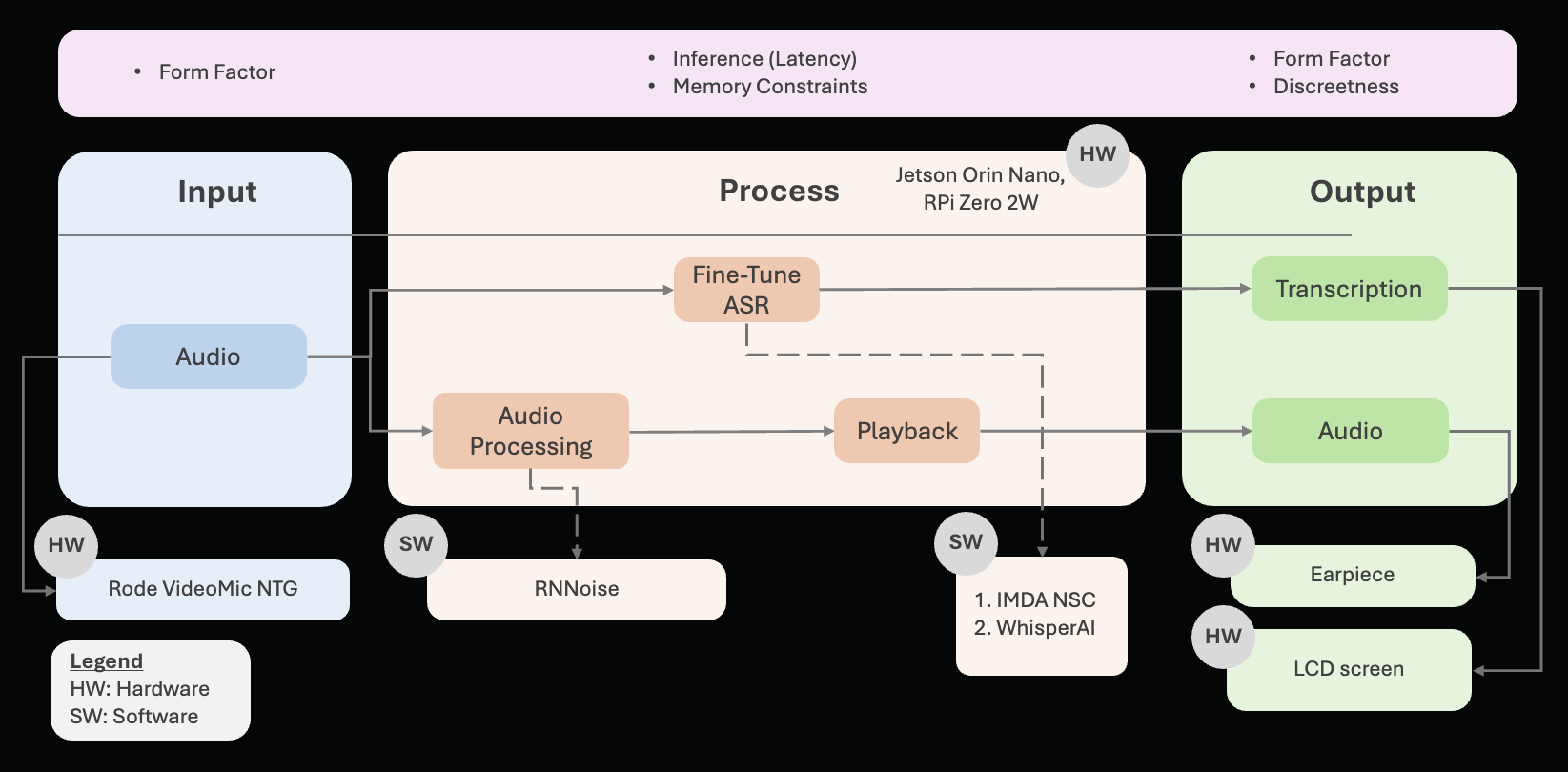
The team has decided to work through the problem in steps. We identified key requirements by mapping a solution to each subproblem:
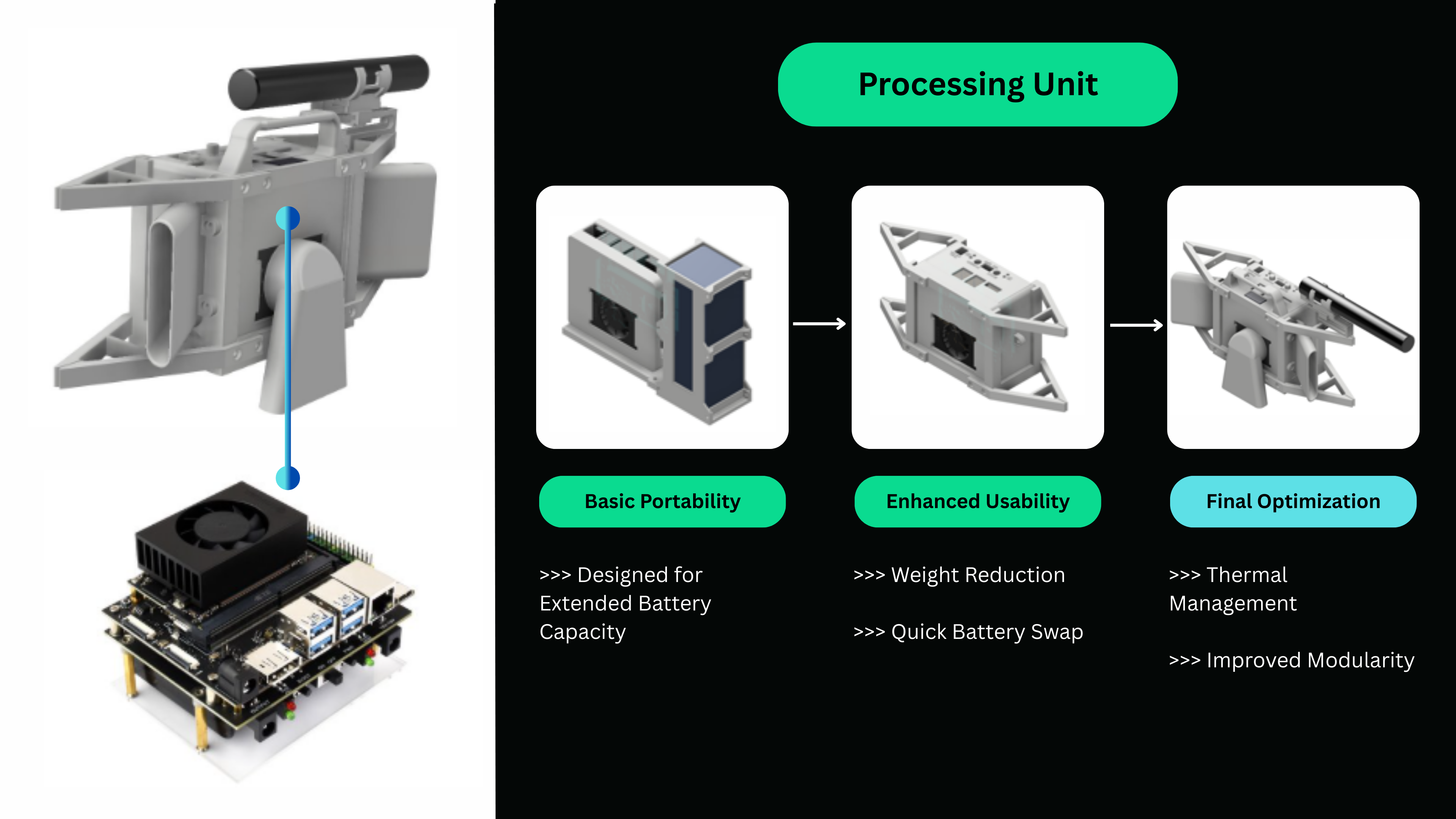
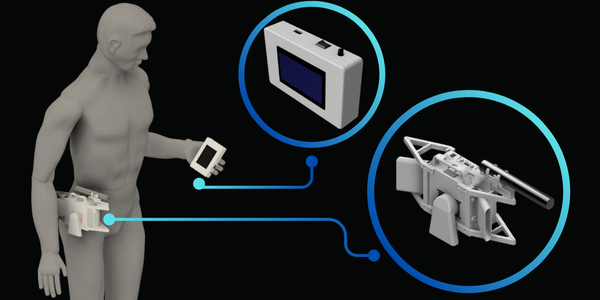
To put it all together, here’s our solution: D’NOISE
A discreet, wearable device that captures and transcribes audio effectively in noisy, offline environments.
It provides dual modality output:










