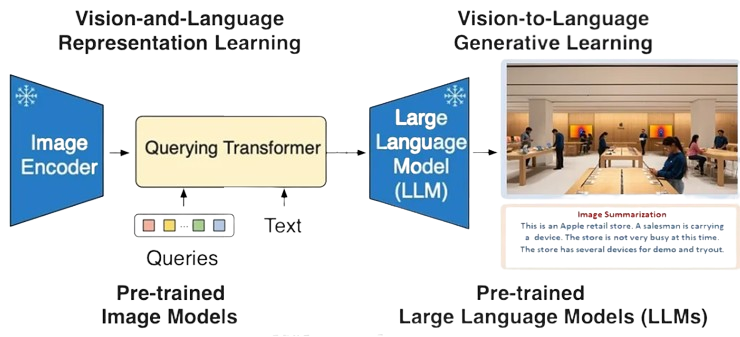
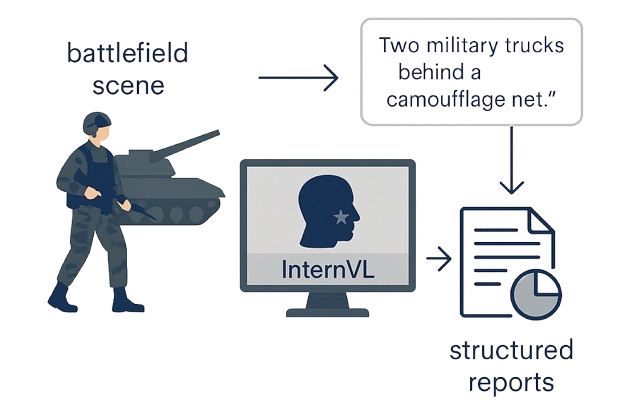
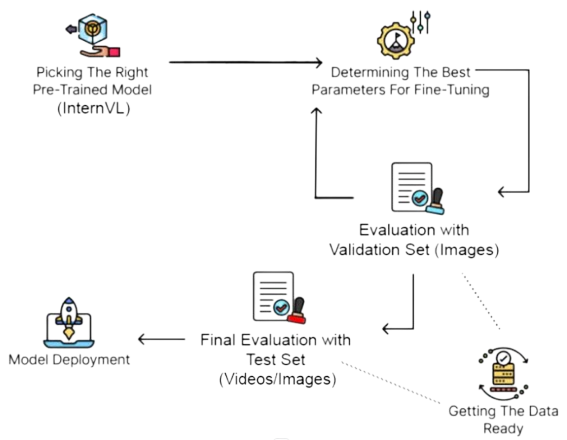
This project on Combat Ready Vision AI, conducted in partnership with ST Engineering, has benefited greatly from the support and guidance of several key individuals.
We extend our gratitude to Prof. Mahamarakkalage Dileepa Yasas Fernando, our capstone mentor, for his expert advice and for encouraging us to challenge the limits of our understanding in this rapidly evolving field.
Our thanks also go to Dr. Benard Tan and Prof Rashmi Kumar from the Centre for Writing and Rhetoric, who provided crucial guidance on communicating complex ideas effectively, thereby enhancing the presentation of our project.
Special appreciation is given to Mr. Wen Siang and Ms. Wen Hui from ST Engineering, our industry mentor, whose insights and guidance were instrumental in the practical success of our project. Her expertise in the industry significantly contributed to the depth and applicability of our research.
The collective wisdom and support of our mentors have been invaluable. We are grateful for their contributions to our project’s success.