AI-Enabled Decision-Making in Dynamic Mission Environments
Introducing IntellAgent, a cutting edge simulation software with efficient route and resource optimisation that empowers the Singapore Armed Forces (SAF) to deliver swift and cost-effective responses during Humanitarian Assistance and Disaster Relief (HADR) missions!
Introducing IntellAgent
Team members
Shaun Neo Kay Hean (CSD), Michael Chun Kai Peng (CSD), Joyce Lim Qi Yan (CSD), Ian Goh Yiheng (CSD), Leong Wen Hou Lester (CSD), Chua Yi Qi Sarah (DAI)
Instructors:
Zhao Na
Writing Instructors:
Bernard Tan Chee Seng
Background
Currently, SAF's mission planning efficiency is hindered by complex processes and overwhelming information, impeding swift responses to dynamic situations critical in life-saving missions where time is paramount.
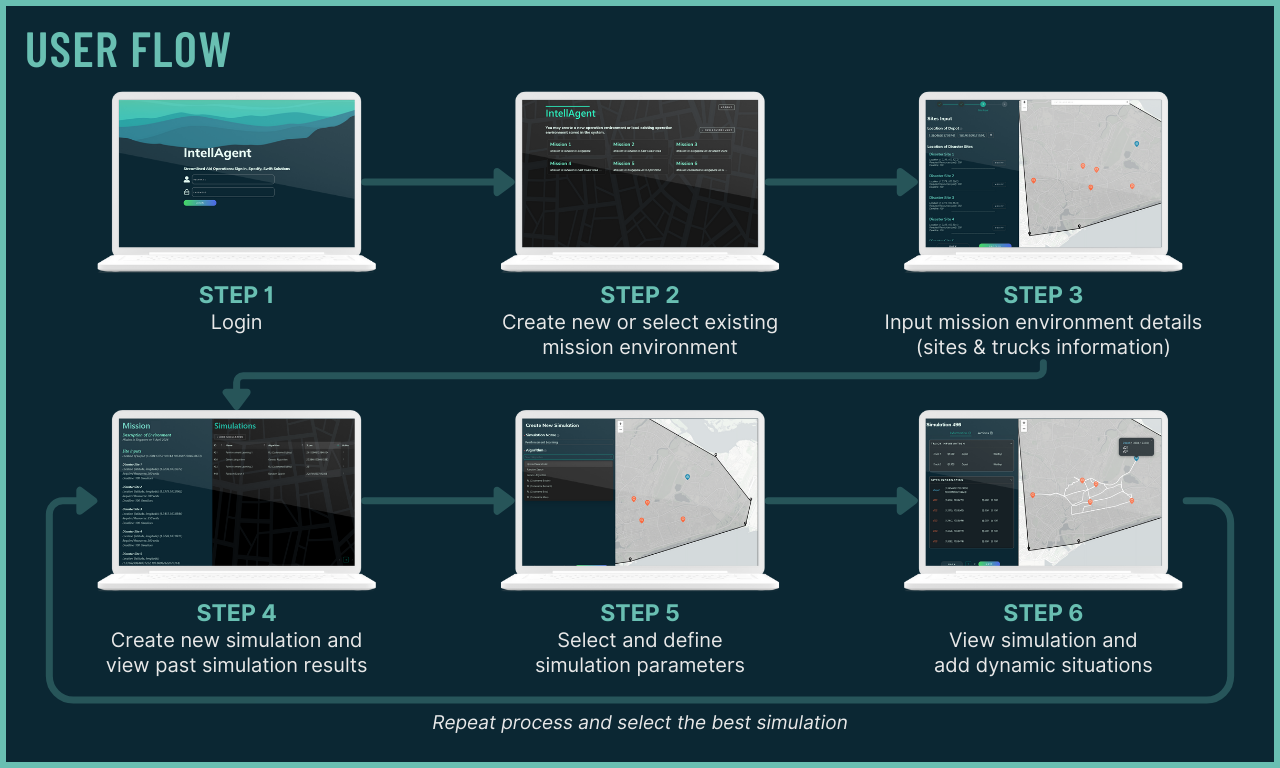
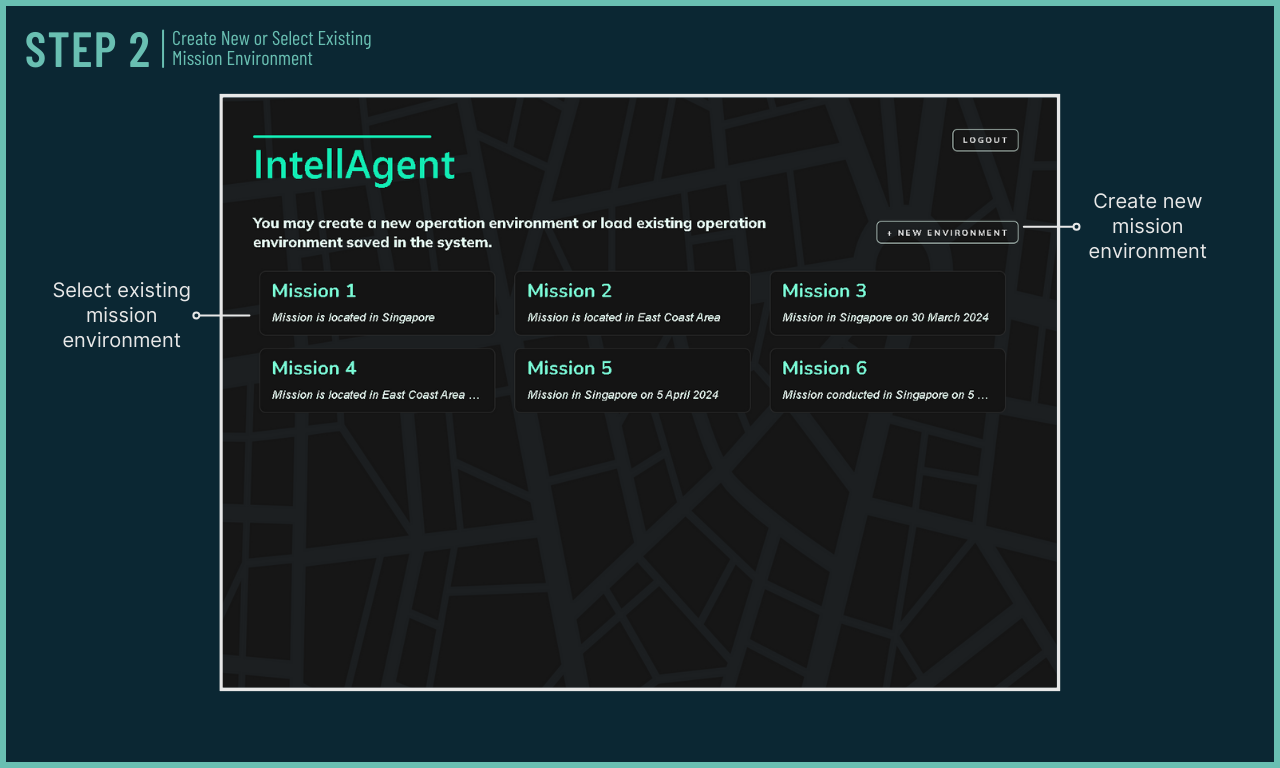
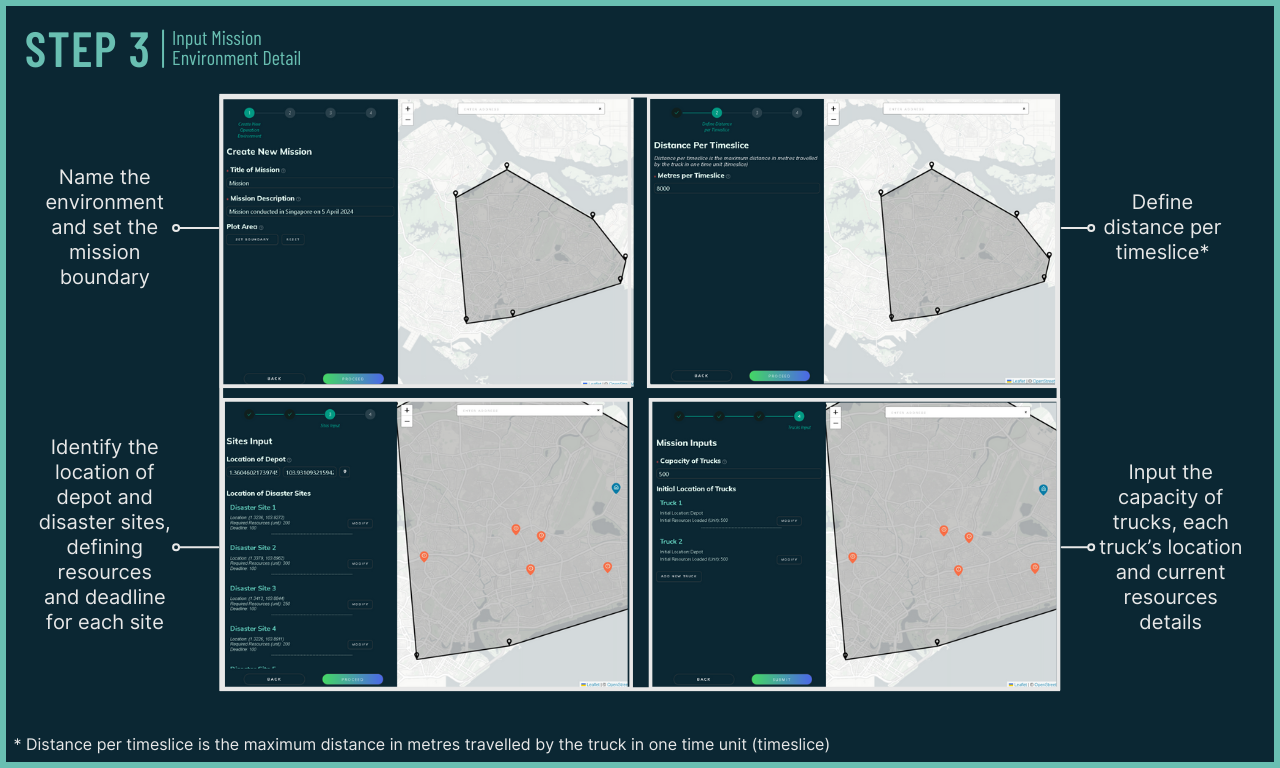
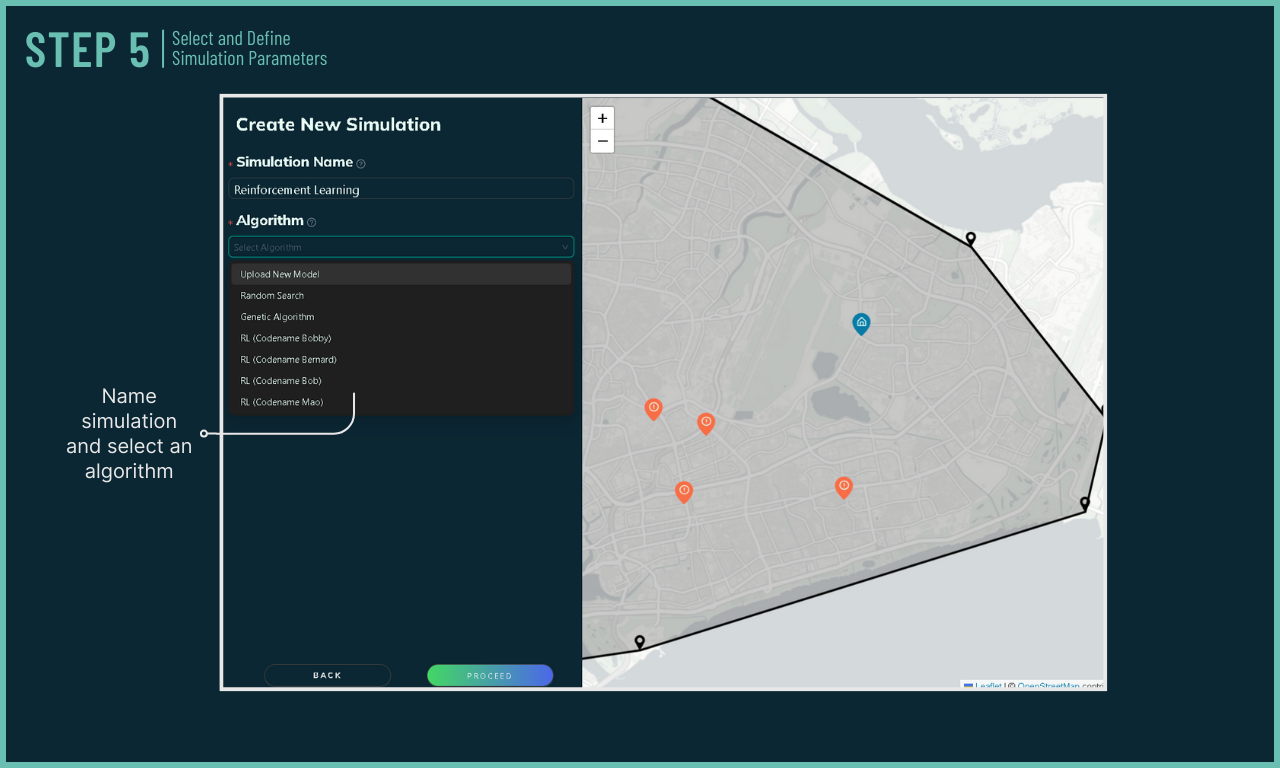
Learn how IntellAgent works!
Key Features
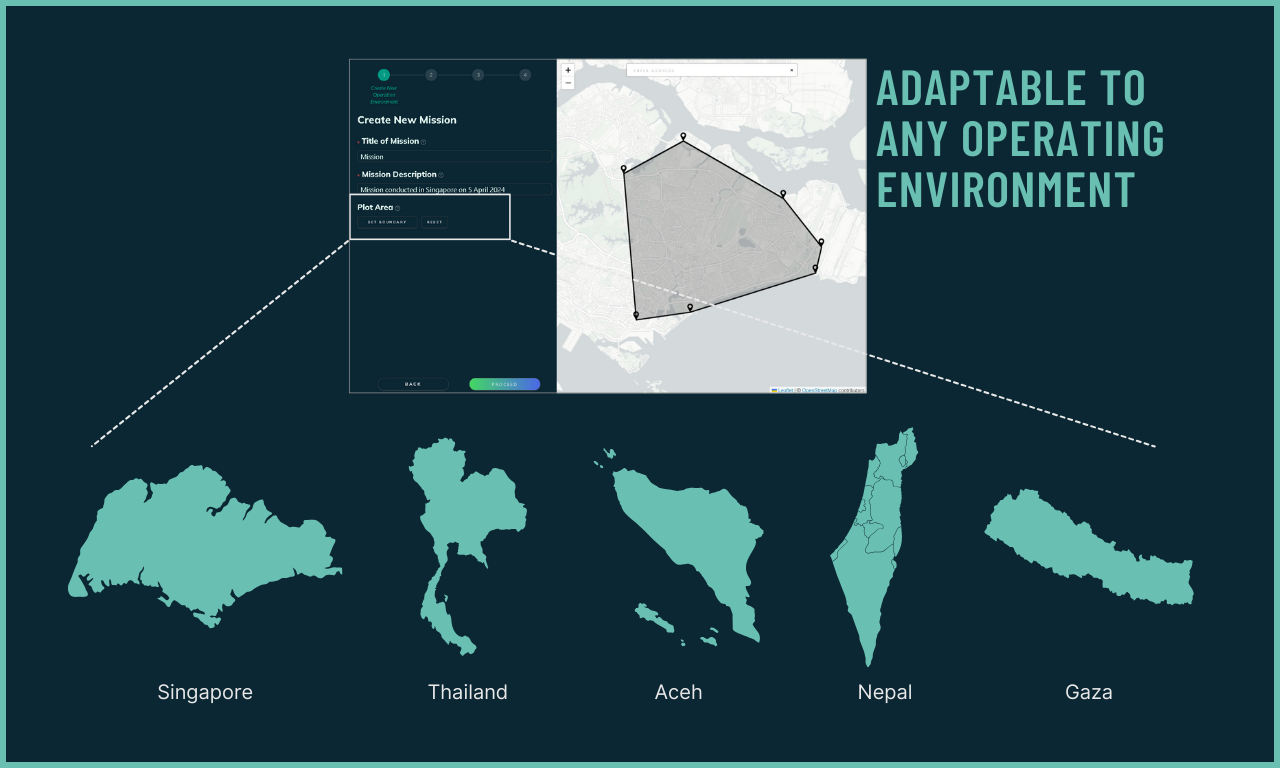
Simple Data Pipeline
Mission planners have the flexibility of setting boundaries to automatically obtain environment data even in unfamiliar environments. This is supported by IntellAgent's quick data aggregation from various sources such as OpenStreetMap.
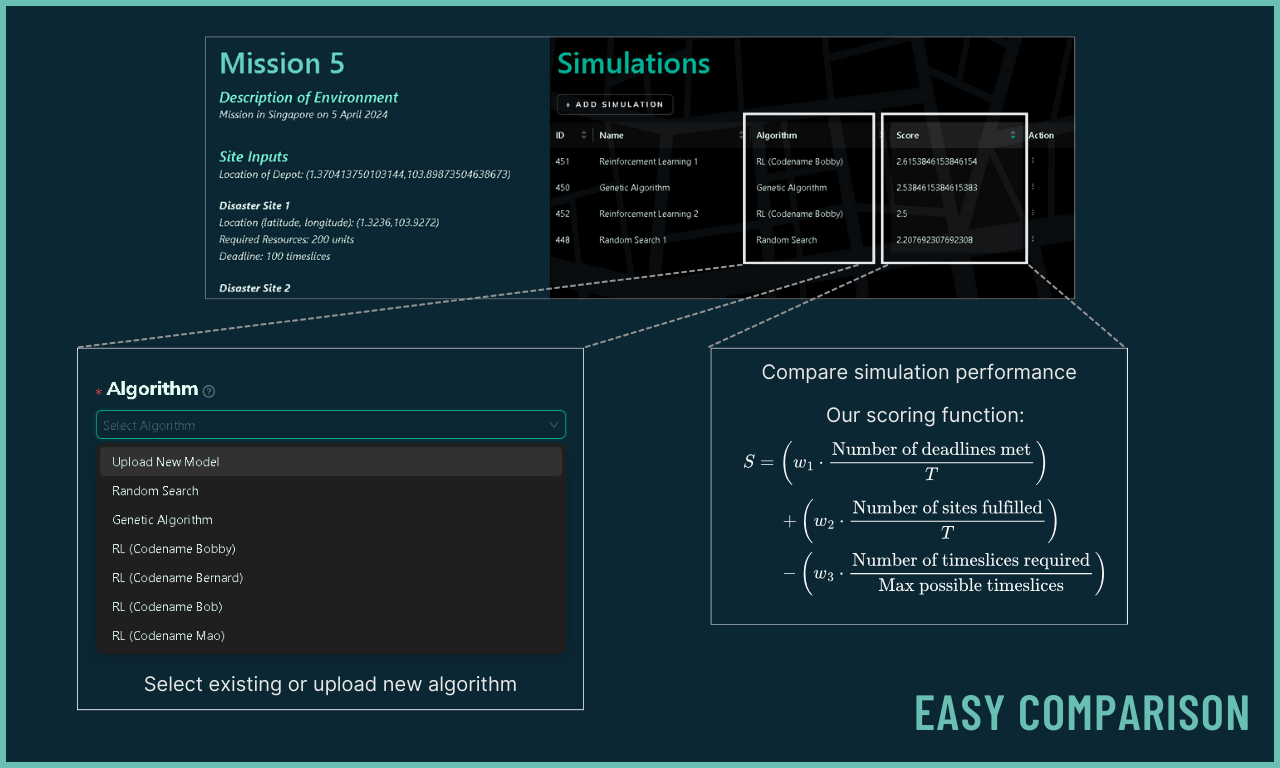
Smart Route Optimisation
IntellAgent offers a wide range of algorithms, such as Reinforcement Learning (RL) and Genetic Algorithms (GA). The performance of the simulations are then evaluated with a score for quick comparison.
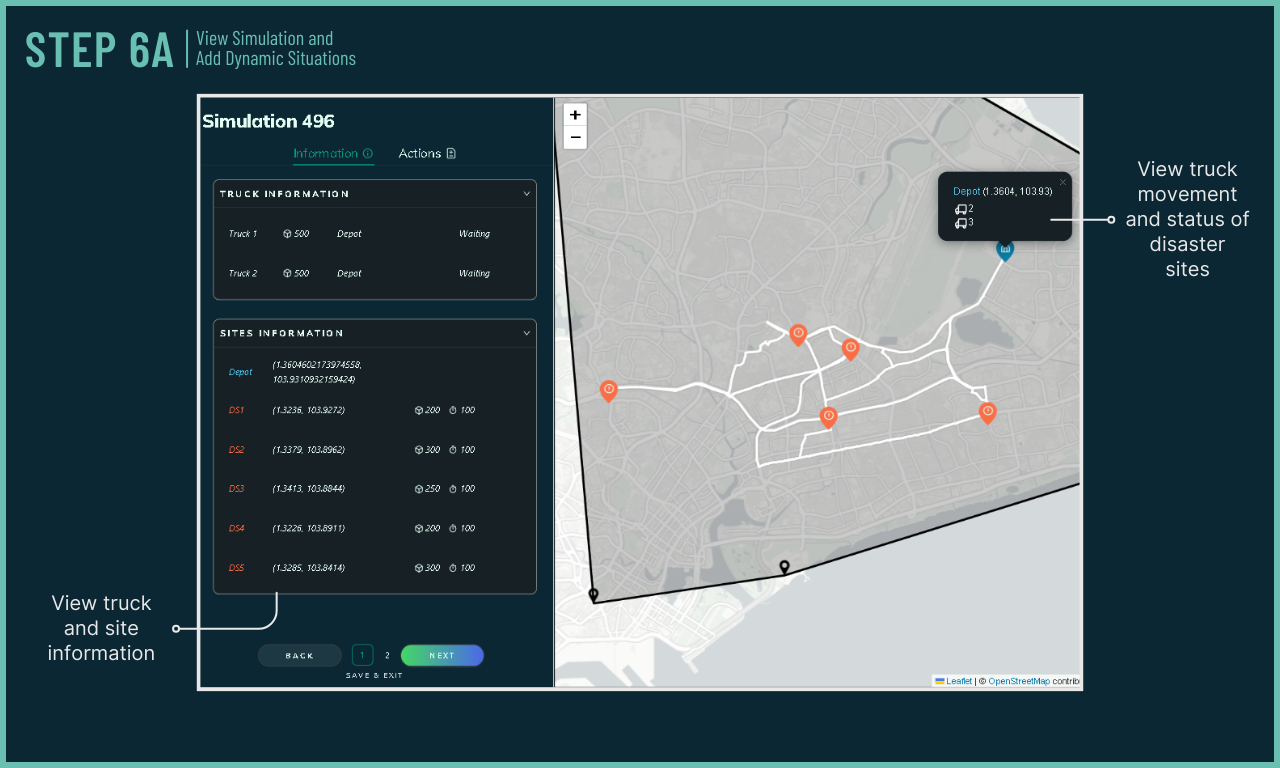
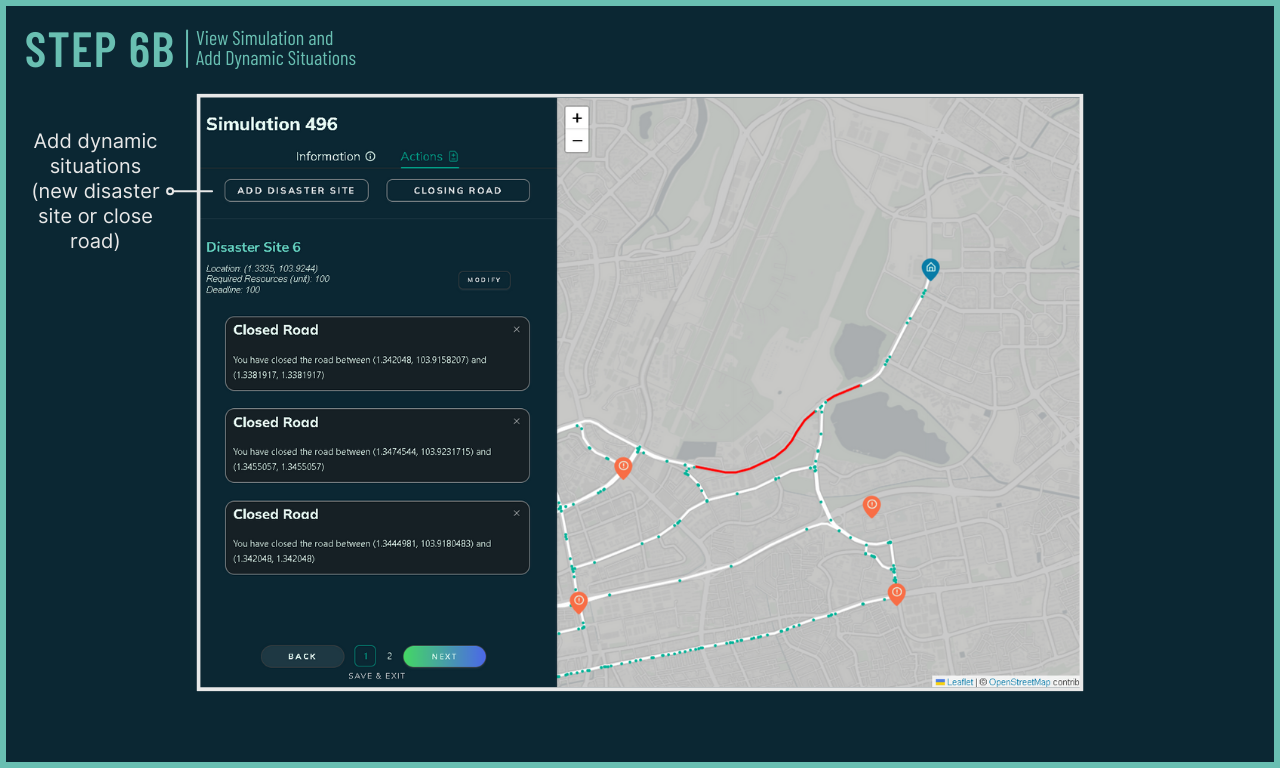
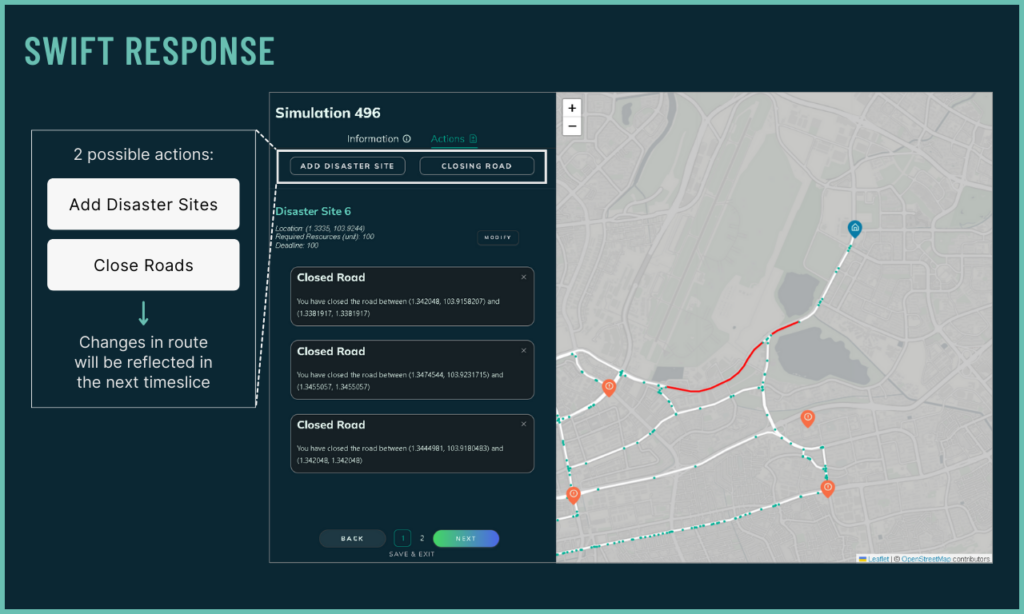
Responsive to Dynamic Situation
Mission planners can easily alter simulation environment during runtime to simulate dynamic actions. Upon altering the simulation's environment, IntellAgent adapts and recalculates a new solution.
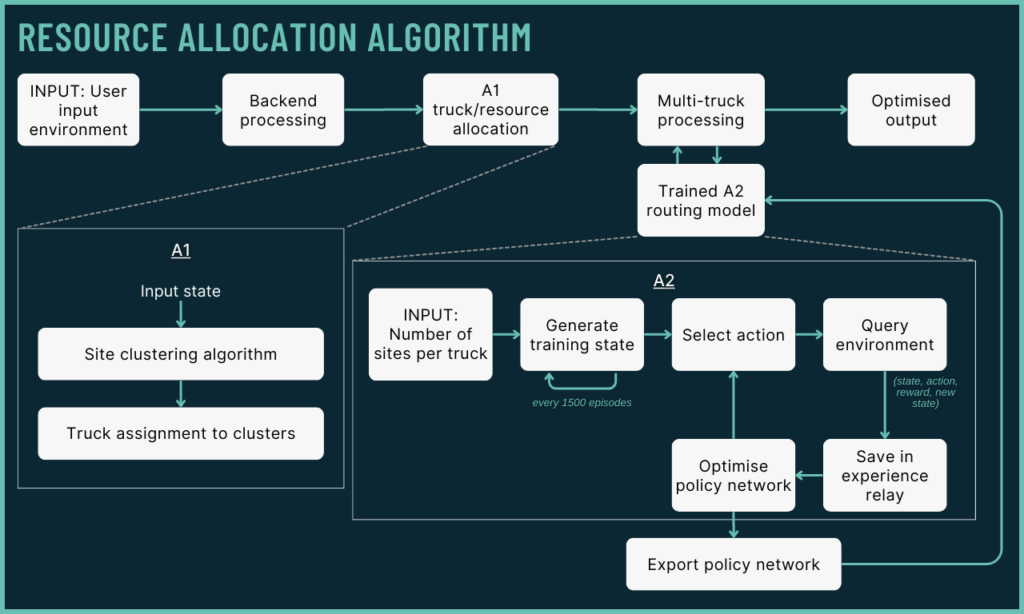
A Hierarchical Approach to Tackle Complex Problems
By breaking down the problem into smaller subproblems, we can optimise at a granular level. First, we assign sites to each truck, based on site locations and required resources. Then, for each truck, we solve the routing problem balancing resource delivery, deadlines, and travel costs.
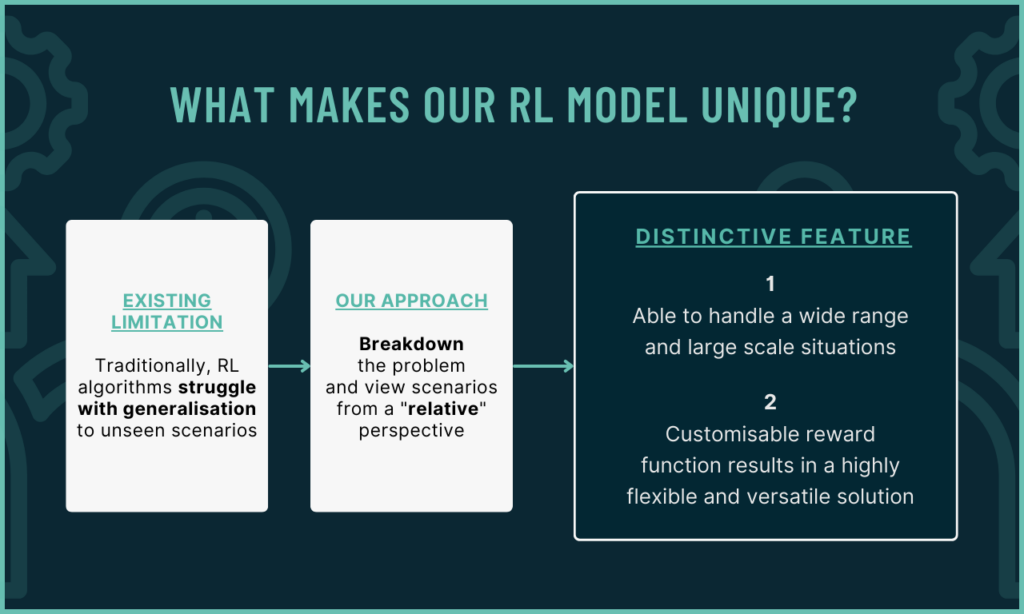
A Novel Perspective for Reinforcement Learning
Our algorithm abstracts the problem and translates it into values relative to the agent's baseline. Agents can handle a wide range of situations beyond predetermined environments. Furthermore, customisable reward function allows the agent to prioritise different objectives, resulting in a highly flexible and versatile solution.
Key Insights
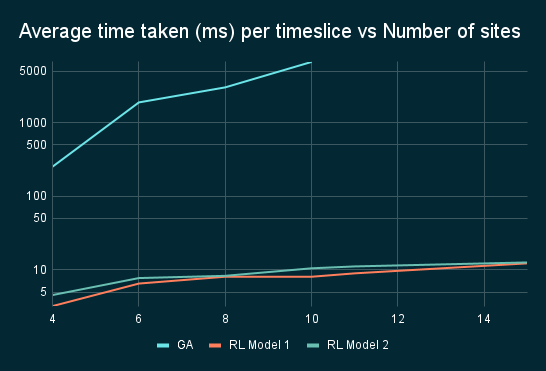
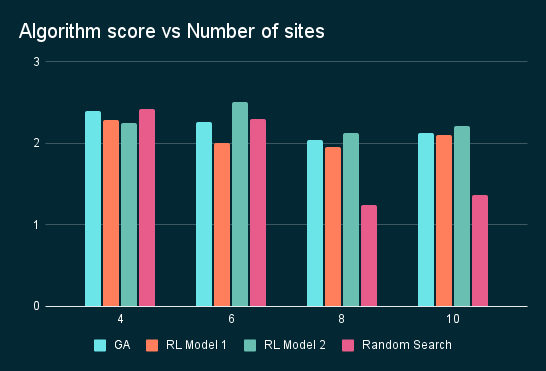
Time taken and memory requirement for GA grows exponentially with number of sites while RL inference remains quick. Our novel approach to RL allows us to calculate optimal solutions quickly even with large number of disaster sites.
While performance of GA and RL are relatively similar, computational resources and time required to perform GA grows exponentially, making it less idealistic.
In collaboration with
We extend our heartfelt gratitude to our industry mentors from DSTA, Marcus and Zhengyi, for their unwavering support and our SUTD mentor, Prof. Zhao Na, for her guidance. Much thanks to Dr. Bernard Tan and the Capstone office for their assistance.
At Singapore University of Technology and Design (SUTD), we believe that the power of design roots from the understanding of human experiences and needs, to create for innovation that enhances and transforms the way we live. This is why we develop a multi-disciplinary curriculum delivered v ia a hands-on, collaborative learning pedagogy and environment that concludes in a Capstone project.
The Capstone project is a collaboration between companies and senior-year students. Students of different majors come together to work in teams and contribute their technology and design expertise to solve real-world challenges faced by companies. The Capstone project will culminate with a design showcase, unveiling the innovative solutions from the graduating cohort.
The Capstone Design Showcase is held annually to celebrate the success of our graduating students and their enthralling multi-disciplinary projects they have developed.