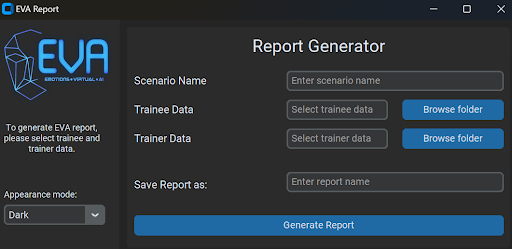
We would like to thank our mentors for their valuable contributions and guidance throughout our Capstone journey:
Our Capstone Instructors, Professor Cheung Ngai-Man and Dr Cyrille Jegourel
Our Writing Instructor, Dr Susan Wong
Our Industry Mentors, Ms Toh Si Hui, Mr Lu Zheng Hao, and Ms Joo Hui Ning








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}